Chromium Cookies 被清除的机制
翻译自:https://blog.yoav.ws/posts/how_chromium_cookies_get_evicted/
我最近被问及是否了解 Chromium 浏览器如何清理或回收其 Cookie。当时我并不清楚,但决定深入研究代码以找出答案。以下是我在探索过程中发现的内容,希望对他人(或至少对未来的自己)有所帮助。
这篇文章中没有太多的叙述性内容,主要是代码指引和参考资料。
TL;DR – 如果您希望某些 Cookie 比其他 Cookie 保留得更久,请将它们设置为高优先级并使用安全(Secure)标记。如果您想明确删除某些 Cookie,请设置一个已过期的 Cookie,其 “domain” 和 “path” 与要删除的 Cookie 匹配。
Cookie Monster 的限制
事实证明,Chromium 的网络堆栈中有一个被称为 “Cookie Monster” 的组件。但即使是怪兽也有其限制。在这种情况下,Cookie Monster 能持有的 Cookie 数量是有限的。它对总的 Cookie 数量(最大 3300 个)以及每个域名的 Cookie 数量(最大 180 个)都有上限。一旦达到这些限制,为了腾出空间,系统会删除一定数量的 Cookie——总共删除 300 个,或每个域名删除 30 个。
鉴于 Cookie 现在是分区存储的,每个分区域名也有相应的限制,但目前这些限制与每个域名的限制相同(即 180 个 Cookie)。
另一个有趣的常量是:在过去 30 天内被访问过的 Cookie 不会被全局清理。也就是说,其他网站无法导致您最近使用的 Cookie 被删除,但如果总的 Cookie 数量超过限制,可能会导致您较旧的 Cookie 被删除。
清理机制
Chromium 的 Cookie Monster 使用了一种变体的最近最少使用(LRU)算法来进行清理。Cookie 会根据访问的时间进行排序,最久未被访问的会首先被删除。访问时间被定义为 Cookie 的创建时间,或最后一次被使用的时间(例如,在请求头中),可能有一分钟的误差。
当设置一个新的 Cookie 时,会触发垃圾回收过程,删除该域名下最久未被访问的 Cookie,以及全局最久未被访问的 Cookie。Cookie Monster 会确定其 “清理目标“——即为了腾出空间需要删除多少个 Cookie。首先,所有已过期的 Cookie 会被删除。然后,清理过程会分轮次进行,直到达到清理目标。
第一轮会针对非安全、低优先级的 Cookie,然后是安全的低优先级 Cookie。至少会保留 30 个此类 Cookie,优先保留安全的。接下来,非安全的中等优先级 Cookie 会被考虑,随后是非安全的高优先级 Cookie。最后,依次考虑安全的中等优先级和高优先级 Cookie。对于中等优先级的 Cookie,至少会保留 50 个(优先保留安全的),而高优先级的则至少保留 100 个。
如果您想明确删除某些较旧的 Cookie,以便为您关心的 Cookie 腾出空间,设置一个已过期的 Cookie 会删除之前的副本,并且不会重新添加它。要设置一个匹配的 Cookie,您需要确保其 “domain” 和 “path” 与您要删除的 Cookie 完全相同。
请注意:Cookie 的优先级是 Chromium 的一个专有功能。它确实很有用,因此未被标准化有些可惜。默认情况下,Cookie 的优先级为中等。
总结
再次希望上述内容对您有所帮助。如果您希望确保特定的 Cookie 比其他的存留时间更长,或者您想删除旧的 Cookie,现在您知道该怎么做了(至少在 Chromium 中是这样)。我尚未深入研究其他浏览器引擎如何处理 Cookie,但我猜测 Safari 可能在操作系统层面(且是闭源的)进行处理。
最后,我希望 Cookie 的优先级功能能够被标准化。这似乎是一个有用的功能,在深入研究代码之前,我并未意识到它的存在。
更新:Mike West 告诉我,曾有一个标准化 “priority” 的草案,但未被工作组采纳。此外,”secure” Cookie 的优先级提升已包含在 RFC6265bis 中。
(本文最初发表于 2024 年 6 月 18 日,作者为 Yoav Weiss。)
Nginx 配合 CloudFlare 获取真实 IP 并限制访问
在最近一次网站部署中,考虑到安全因素,希望将源站完全隐藏在 CF 后,只允许 CF 访问,并尽可能的减少信息泄漏。
获取真实客户端 IP
由于经过 CloudFlare 代理后,Nginx 看到的 remote ip 其实是 CF 的 IP 地址。因此需要通过 Nginx 的 ngx_http_realip_module,还原出真实的客户端 IP。这一步在 CloudFlare 有详细的文档说明。
简单来说,当发现请求 IP 为 CF 的 IP 段时,读取 CF-Connecting-IP 头,并将其中的 IP 设置为客户端 IP。CF 的 IP 段可以通过 API 获取。以下是一个脚本可以生成相关的配置:
#!/bin/bash
# 脚本:获取 Cloudflare IP 列表并生成 Nginx 配置
# 输出文件
IP_CONFIG_FILE="cf_ips.conf"
# 清空输出文件
> "$IP_CONFIG_FILE"
# Cloudflare IP 列表 API 端点
CLOUDFLARE_API_URL="https://api.cloudflare.com/client/v4/ips"
# 生成 set_real_ip_from 配置
echo "# Cloudflare IPv4 IPs" >> "$IP_CONFIG_FILE"
curl -s "$CLOUDFLARE_API_URL" | jq -r '.result.ipv4_cidrs[]' | while read -r ip; do
echo "set_real_ip_from $ip;" >> "$IP_CONFIG_FILE"
done
echo -e "\n# Cloudflare IPv6 IPs" >> "$IP_CONFIG_FILE"
curl -s "$CLOUDFLARE_API_URL" | jq -r '.result.ipv6_cidrs[]' | while read -r ip; do
echo "set_real_ip_from $ip;" >> "$IP_CONFIG_FILE"
done
# 添加 real_ip_header 配置
echo -e "\n# Set real IP header" >> "$IP_CONFIG_FILE"
echo "real_ip_header CF-Connecting-IP;" >> "$IP_CONFIG_FILE"脚本运行后会生成 cf_ips.conf 文件,内含 set_real_ip_from 和 real_ip_header 配置,在 http 段 include 该文件,即可自动为所有 server 自动设置真实客户端 IP。
限制仅 CloudFlare IP 访问
解决了真实客户端 IP 的问题后,接下来就是如何做到仅限 CF IP 访问。由于该 Nginx 托管了多个 server,因此并不希望直接从防火墙层面拒绝所有非 CF IP 访问。那么从 Nginx 侧,第一时间想到的就是用 ngx_http_access_module 的方式,仅放过 CF IP 段:
# Cloudflare IPv4 Allow
allow 173.245.48.0/20;
allow 103.21.244.0/22;
allow 103.22.200.0/22;
allow 103.31.4.0/22;
allow 141.101.64.0/18;
allow 108.162.192.0/18;
allow 190.93.240.0/20;
allow 188.114.96.0/20;
allow 197.234.240.0/22;
allow 198.41.128.0/17;
allow 162.158.0.0/15;
allow 104.16.0.0/13;
allow 104.24.0.0/14;
allow 172.64.0.0/13;
allow 131.0.72.0/22;
# Cloudflare IPv6 Allow
allow 2400:cb00::/32;
allow 2606:4700::/32;
allow 2803:f800::/32;
allow 2405:b500::/32;
allow 2405:8100::/32;
allow 2a06:98c0::/29;
allow 2c0f:f248::/32;
# Default deny
deny all;但是添加了这段配置后,发现不论是否通过 CF 访问,所有请求均会被拦截,返回 403。搜索相关文章1后发现,这是因为 ngx_http_realip_module 已经先执行完毕了,此时 ngx_http_access_module 拿到的已经是被修改了的真实客户端 IP,自然无法通过检测,被拒绝访问。
为了解决该问题,我们需要使用其他手段来进行访问控制。查阅相关资料后发现,ngx_http_geo_module 是个非常好的选择。相关配置如下:
geo $realip_remote_addr $is_cf {
default 0;
# Cloudflare IPv4 Allow
173.245.48.0/20 1;
103.21.244.0/22 1;
103.22.200.0/22 1;
103.31.4.0/22 1;
141.101.64.0/18 1;
108.162.192.0/18 1;
190.93.240.0/20 1;
188.114.96.0/20 1;
197.234.240.0/22 1;
198.41.128.0/17 1;
162.158.0.0/15 1;
104.16.0.0/13 1;
104.24.0.0/14 1;
172.64.0.0/13 1;
131.0.72.0/22 1;
# Cloudflare IPv6 Allow
2400:cb00::/32 1;
2606:4700::/32 1;
2803:f800::/32 1;
2405:b500::/32 1;
2405:8100::/32 1;
2a06:98c0::/29 1;
2c0f:f248::/32 1;
}其中,$realip_remote_addr 是 ngx_http_realip_module 提供的变量,存储了原始的客户端地址。通过 CF 访问的情况下,这个变量存储的就是原始的 CF 地址。$is_cf 是用于储存中间结果的变量。如果原始客户端地址在 CF IP 段,则会被设置为 1,否则为 0。
有了这个变量之后,我们就可以使用 ngx_http_rewrite_module 来进行判断,并拒绝访问。在需要的地方增加如下代码:
if ($is_cf = 0) {
return 444;
}即可拒绝掉所有非 CF 访问的情况。
使用 OpenResty
如果在使用 OpenResty,那么有更简单的方式2可以做这个事情。借助 access_by_lua_block,我们可以直接在 lua 里访问相关变量进行判断,并拒绝非 CF 的访问:
access_by_lua_block {
if ngx.var.remote_addr == ngx.var.realip_remote_addr then
return ngx.exit(ngx.HTTP_FORBIDDEN)
end
}原理其实也很简单,如果 ngx.var.remote_addr 和 ngx.var.realip_remote_addr 是相同的,则证明 ngx_http_realip_module 没有起作用,那么说明原始访问 IP 一定不在 CF IP 段内。
注意事项
- 有条件的情况下(即 Nginx 所有 server 都托管在 CF),应使用防火墙直接拒绝所有非 CF IP 的 TCP 链接
- 由于
if指令只能使用在server,location使用,因此该方法在多个server内,需要重复配置 - 由于
ssl_reject_handshake无法在if内使用,因此如果攻击者猜对了 server_name,那么证书信息依然会泄漏,存在被探测到源站的可能
参考文档
QNAP 新版 License Center 校验流程逆向
最近新添置了两个支持 ONVIF 协议的摄像头,想使用 QNAP 的 QVR 进行录像。但是打开 QVR 发现,只能添加两个通道,后续新的通道需要按年付费解锁。依稀记得原先是有 8 个免费通道可用的,于是打开官方文档,发现:
| 系统 | 软件 | 授权 |
| QTS | QVR Pro | 自带 8 通道 |
| QTS | QVR Elite | 自带 2 通道 |
| QuTS hero | QVR Elite | 自带 2 通道 |
原来官方提供的 8 通道 QVR Pro 只支持 QTS 系统,不支持基于 ZFS 的 QuTS hero 系统。既然官方不支持,那只能自己动手了。
TL; DR
- GPT 太好用了,大大提升逆向效率
- 新版校验用的 Public Key 经过简单的凯撒密码加密后打包在
libqlicense.so中 - LIF 文件的 floating 相关字段需要干掉,否则会联机校验
激活流程
在研究的过程中,发现已有前人详细分析了激活流程的各个步骤,分析了各个文件的存储、编码、加密、验证格式,并编写了相关脚本和代码。具体文章在这里,此处不多做赘述:
https://jxcn.org/2022/03/qnap-license
尝试动手
参考文章,尝试在 NAS 上进行操作。结果发现,找不到文章中提及的 qlicense_public_key.pem 文件,全盘搜索后发现依然找不到该文件。查看文章评论发现,似乎官方在 23 年左右修改了一次校验逻辑,去掉了该文件。所有 23 年之后发布的版本,都无法使用替换 key 文件的方式进行激活。
重新分析
虽然官方修改了相关逻辑,但是有前人经验参考,还是很快发现了关键所在。
先用 IDA 打开 qlicense_tool ,找到离线激活的处理函数,发现对输入进行简单处理后直接调用了 qcloud_license_offline_activate 函数,位于 libqlicense.so 动态链接库中。这个函数在几层调用之后,最终调用了 qcloud_license_internal_verify 函数,对 LIF 文件的签名进行了计算。
由于静态分析不太容易理清逻辑,于是上 GDB 准备直接调试。找了下发现 MyQNAP Repo 里有编译好的 GDB,但是安装却失败了。研究了下发现是作者把 X86 和 X41 的链接搞反了。X86 下载到的包是 X41 的,导致安装失败。于是手动下载了正确的包之后安装,一切顺利。
通过 gdb 调试发现,qcloud_license_internal_verify 函数的第一个入参就是校验用的 Public Key,打出来长这样:
-----BEGIN PUBLIC KEY-----
MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAEDJcPoMIFyYDlhTUzNSeT/+3ZKcByILoI
Fw8mLv07Hpy2I5qgAGQu66vF3VUjFKgpDDFKVER9jwjjmXUOpoCXX4ynvFUpEM25
ULJE86Z6WjcLqyG03Mv6d3GPYNl/cJYt
-----END PUBLIC KEY-----
通过 hook fopen 函数,想找到这个 key 存储在哪个文件,但是发现并没有结果。于是想到,这段 key 可能被打进了 so 文件本身,于是通过 Strings 搜索,但是依然没有找到相关字符串。
一筹莫展之际,在调用链路上乱点,突然注意到这样一段奇怪的代码(IDA 还原得出):
while ( 1 )
{
result[v3] = (v1[v3] + 95) % 128;
if ( ++v3 == 359 )
break;
result = (_BYTE *)*a1;
}多看两眼之后意识到,这就是凯撒密码。(虽然凯撒密码现在看来其实更应该算是编码而非加密,但是考虑到确实有相关定义,因此后续均表述为加密和解密。)也就是说,之所以在 Strings 内找不到相关字符串,是因为写入的是通过凯撒密码加密后的字符串。于是把这段丢给 GPT,让它写个加密和解密的代码:
# -*- coding: utf-8 -*-
def decode(input_string):
result = []
for char in input_string:
# 将每个字符的 ASCII 值加 95,然后对 128 取模
encoded_char = (ord(char) + 95) % 128
result.append(chr(encoded_char))
return ''.join(result)
def encode(encoded_string):
result = []
for char in encoded_string:
# 逆向解码:恢复原始字符
decoded_char = (ord(char) - 95) % 128
result.append(chr(decoded_char))
return ''.join(result)
original_text = """-----BEGIN PUBLIC KEY-----
MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAEDJcPoMIFyYDlhTUzNSeT/+3ZKcByILoI
Fw8mLv07Hpy2I5qgAGQu66vF3VUjFKgpDDFKVER9jwjjmXUOpoCXX4ynvFUpEM25
ULJE86Z6WjcLqyG03Mv6d3GPYNl/cJYt
-----END PUBLIC KEY-----"""
encoded_text = encode(original_text)
decoded_text = decode(encoded_text)
print("Original:", original_text)
print("Encoded:", encoded_text)
print("Decoded:", decoded_text)跑了一下,得到实际存储的字符串:
NNNNNcfhjoAqvcmjdAlfzNNNNN+niz\u0018fbzil\u0010{j\u001b\u000bQdbrzglUffbdjez\bbfek\u0004q\u0010njg\u001aze\r\tuv\u001bot\u0006uPLT{l\u0004c\u001ajm\u0010j+g\u0018Y\u000em\u0017QXi\u0011\u001aSjV\u0012\bbhr\u0016WW\u0017gTwv\u000bgl\b\u0011eeglwfsZ\u000b\u0018\u000b\u000b\u000eyvp\u0011\u0010dyyU\u001a\u000f\u0017gv\u0011fnSV+vmkfYW{Wx\u000b\u0004m\u0012\u001ahQTn\u0017W\u0005Thqzo\rP\u0004kz\u0015+NNNNNfoeAqvcmjdAlfzNNNNN由于开头和结尾的 ----- 会被加密为 NNNNN 因此直接在 Strings 中搜索,顺利定位到相关资源,位于 .rodata 段 38B40 的位置,长度 212。
接下来操作就简单了,生成一对新的 key 之后,直接替换指定位置即可。注意,由于长度是写死在代码里的,因此二者必须等长,否则可能会出现无法预料的错误。
再丢给 GPT 写个十六进制替换的脚本:
# -*- coding: utf-8 -*-
import binascii
def hex_to_bytes(hex_str):
"""将16进制字符串转换为字节数据。"""
return binascii.unhexlify(hex_str)
def patch_file(file_path, search_hex, replace_hex):
# 将16进制模式转换为字节数据
search_bytes = hex_to_bytes(search_hex)
replace_bytes = hex_to_bytes(replace_hex)
# 检查替换块的长度是否匹配
if len(search_bytes) != len(replace_bytes):
raise ValueError("Length mismatch! 搜索模式和替换内容长度必须相同!")
# 读取文件内容
with open(file_path, "rb") as f:
data = f.read()
# 查找并替换内容
patched_data = data.replace(search_bytes, replace_bytes)
# 如果没有找到匹配的内容
if data == patched_data:
print("No Match. 没有找到匹配的内容。")
else:
# 将修改后的内容写回文件
with open(file_path, "wb") as f:
f.write(patched_data)
print("Patch success. 文件已成功更新。")
# 使用示例
file_path = "libqlicense.so" # 需要打补丁的文件路径
old_hex = "4e4e4e4e4e6366686a6f417176636d6a64416c667a4e4e4e4e4e2b6e697a1866627a696c107b6a1b0b516462727a676c55666662646a657a086266656b0471106e6a671a7a650d0975761b6f740675504c547b6c04631a6a6d106a2b6718590e6d17515869111a536a56120862687216575717675477760b676c08116565676c7766735a0b180b0b0e7976701110647979551a0f17677611666e53562b766d6b6659577b57780b046d121a6851546e1757055468717a6f0d50046b7a152b4e4e4e4e4e666f65417176636d6a64416c667a4e4e4e4e4e" # 要搜索的16进制字符串
new_hex = "4e4e4e4e4e6366686a6f417176636d6a64416c667a4e4e4e4e4exxx4e4e4e4e4e666f65417176636d6a64416c667a4e4e4e4e4e" # 替换为的16进制字符串
# 执行替换操作
patch_file(file_path, old_hex, new_hex)
这里使用 Hex Encoding 的原因是加密后的字符串存在一些非 ASCII 字符。
替换后,用原作者的相关脚本和工具,生成了一个 LIF,尝试使用 qlicense_tool 激活。此时发现,激活死活失败,但是调试发现 verify 实际已经过了。研究了好久之后,发现是 Console Management 工具导致的。由于 qlicense_tool 在激活过程中会运行被激活服务的脚本检测 License 正确性,而 Console Management 拦截了相关命令,导致返回包不是合法的 json,导致失败。在系统设置内关闭 Console Management 后,激活成功。
检测报错
本以为到此激活就成功了。结果打开许可证中心之后,发现许可证无效了。查阅相关日志,发现许可证中心发送了一个 POST 请求到 https://license.myqnapcloud.io/v1.1/license/device/installed ,然后报错许可不属于该设备,然后将许可改为失效。
阅读原作者相关文章,结合代码,发现是因为原作者是为了 QuTS Cloud 设计的代码,由于 Cloud 版没有离线激活功能,所以会定期刷新 Token,这里一刷新就发现许可有问题了。于是修改代码,将 LIF 内的 floating 相关字段全部干掉。包括:
FloatingUUID
FloatingToken
LicenseCheckPeriod重新生成 LIF 文件,再次激活,已经不会向 myqnapcloud 验证激活信息了。
OpenResty AES 函数密钥生成原理
最近遇到一个场景,需要在 OpenResty 里使用 AES 对数据进行加密。但是看了一下官方提供的 AES 库,如果数据密码的话,并没有返回实际使用的 key 和 IV,因此查看了一下源码,研究了一下 key 生成的方式,方便其他语言使用。
密钥生成逻辑的核心代码在这:
function _M.new(self, key, salt, _cipher, _hash, hash_rounds, iv_len, enable_padding)
...
local _hash = _hash or hash.md5
local hash_rounds = hash_rounds or 1
...
if C.EVP_BytesToKey(_cipher.method, _hash, salt, key, #key,
hash_rounds, gen_key, gen_iv)
~= _cipherLength
then
return nil, "failed to generate key and iv"
end
end其中最核心的部分就是使用了 EVP_BytesToKey 这个函数,进行密钥扩展。这个函数是 OpenSSL 库提供的函数,相关说明在这:
https://www.openssl.org/docs/man3.1/man3/EVP_BytesToKey.html
注意!该函数并不安全!一般不建议在生产中使用该函数!应当使用安全的密钥衍生函数(KDF)!
阅读文档,该函数的主要做法就是对提供的密码进行 hash,如果长度不够 key 或 iv 的要求,则继续进行 hash,直到长足足够为止。
第一轮 hash 直接拼接给定的密码和 salt,从第二轮开始,则将上一轮的结果附加在密码和 salt 前,然后再次进行 hash 操作。注意这里从第二轮开始附加的上一轮结果是二进制结果,如果希望手动使用工具计算的话,需要将 hex 编码或 base64 编码后的结果先进行解码,再附加在输入前。
用 Go 模拟这个过程的代码如下:
package main
import (
"crypto/sha256"
"fmt"
)
// EVPBytesToKey 模拟 OpenSSL EVP_BytesToKey 方法
func EVPBytesToKey(password, salt []byte, keyLen, ivLen int) (key, iv []byte) {
var (
concatenatedHashes []byte
previousHash []byte
currentHash []byte
hash = sha256.New()
)
for len(concatenatedHashes) < keyLen+ivLen {
hash.Reset()
// 如果不是第一轮,将上一轮的哈希值加到当前哈希的输入中
if previousHash != nil {
hash.Write(previousHash)
}
// 加入密码和盐值
hash.Write(password)
hash.Write(salt)
// 当前哈希
currentHash = hash.Sum(nil)
// 添加到累积哈希中
concatenatedHashes = append(concatenatedHashes, currentHash...)
// 为下一轮准备
previousHash = currentHash
}
// 提取密钥和 IV
key = concatenatedHashes[:keyLen]
iv = concatenatedHashes[keyLen : keyLen+ivLen]
return key, iv
}
func main() {
password := []byte("password")
salt := []byte("salt")
keyLen := 32 // AES-256 需要的密钥长度
ivLen := 16 // AES 的 IV 长度
key, iv := EVPBytesToKey(password, salt, keyLen, ivLen)
fmt.Printf("Key: %x\nIV: %x\n", key, iv)
}无痛解决 TeslaMate 访问 OpenStreetMap API 的问题
TeslaMate 是一款特斯拉汽车专用的增强工具,使用了破解的官方 App 的 API,将车机记录的大量信息进行了导出和展示,极大的增强了特斯拉车主的使用体验。
但是由于一些原因,中国特斯拉的汽车的数据都是存放在中国大陆,且不允许境外 IP 访问。因此,中国车主想要使用 TeslaMate,则必须在境内部署相关的服务。
不过,境内部署虽然可以解决访问 Tesla API 的问题,却也带来了新的问题,就是调用境外 API 的时候会出现错误,导致部分功能无法使用。
具体来说,TeslaMate 使用了 OpenStreetMap 提供的 API,用来将经纬度坐标转换为地名。然而,OpenStreetMap 的域名在境内是无法访问的,因此会导致解析坐标点的时候出现失败,导致在 Grafana 的 Drives(行程) 面板不显示行程的起止地址。
为了解决这个问题,我首先想到了设置 http_proxy 等环境变量的方式。但是搜索之后发现,似乎 TeslaMate 并不会读区这几个环境变量,因此无法使用这种方式强制走代理访问相关 API。而且,由于 Tesla 本身的 API 不能走代理访问,必须使用中国 IP 访问,因此如果要使用这种方式的话,还需要配置 Proxy 的分流策略,非常麻烦。
综合考虑各种方案,我最终选择了 sniproxy 的方式。sniproxy 是允许在不解密流量本身的情况下,进行 SSL/TLS 流量转发的方案。使用 sniproxy 时,只需要将目标域名的 IP 强制指向 sniproxy 的 IP 地址(如修改 /etc/hosts),既可以完成代理。
方案一:直接在本地运行 sniproxy
- 优点:不占用母鸡的 443 端口,不影响现有服务
- 缺点:配置较为繁琐,需要两个额外的容器互相配合
考虑到搭建 sniproxy 需要占用一个 IP 的 443 端口,因此我决定在 docker compose 内增加 sniproxy 的相关容器,来做到不占用母鸡的 443 端口的目的。由于 sniproxy 是运行在 TeslaMate 同一台机器上的,因此还需要一个额外的代理来将流量转发出去。这一步有很多方案,使用 warp+、ss、v2 等均可实现,我选择使用 v2 的方案。
最终修改后的 docker-compose.yaml 新增的内容如下:
sniproxy:
image: sniproxy
restart: always
command: ./sniproxy
depends_on:
- xray
networks:
default:
aliases:
- nominatim.openstreetmap.org
xray:
image: teddysun/xray:latest
restart: always
volumes:
- ./xray:/etc/xray其中,sniproxy 镜像是对 https://github.com/XIU2/SNIProxy 项目的简单包装,将配置文件写在了镜像内。配置内容如下:
# 监听端口(注意需要引号)
listen_addr: ":443"
# 可选:启用 Socks5 前置代理
enable_socks5: true
# 可选:配置 Socks5 代理地址
socks_addr: xray:40000
# 可选:允许所有域名(会忽略下面的 rules 列表)
#allow_all_hosts: true
# 可选:仅允许指定域名
rules:
- openstreetmap.org这里的 socks_addr 为下方 xray 容器内的 socks 代理监听地址。
这段配置的重点在于,sniproxy 容器配置了 network alias。这个选项的作用是,告诉 docker compose,将指定的域名解析到当前容器。因此,加上了这段配置后,docker 容器内解析 nominatim.openstreetmap.org 这个域名,会自动得到 sniproxy 容器的 docker 网络的 IP,达到将 OpenStreetMap 的 API 请求自动导向 sniproxy,进而导向 xray 代理的目的。
方案二:使用单独的服务器部署 sniproxy
- 优点:配置简单,无需额外容器
- 缺点:需要额外的服务器部署 sniproxy,需要占用一个 443 端口
当然,如果有多余的服务器,可以提供一个 443 端口的话,就不用这么麻烦了。直接在服务器上搭建好 sniproxy,然后在 docker-compose.yaml 内的 teslamate 容器配置里增加下面这段就可以了:
extra_hosts:
nominatim.openstreetmap.org: sniproxy_server_ip这段配置等同于在 teslamate 的 docker 容器的 /etc/hosts 文件内,写入了域名与 IP 的映射关系,因此所有的 OpenStreetMap 相关的 API 请求,都会被导向 sniproxy 的 IP 地址。
P.S. 其实使用 nginx 的 stream 模块,配合 stream_ssl stream_ssl_preread 两个模块,可以做到不影响现有的网站服务的前提下,与 sniproxy 兼容。但是此方法需要对现有的 nginx 配置进行较大的改动,而我本人的 nginx 配置有十几个文件,实在是不想改,因此就放弃了这种方式。
罗技 Logi MX 系列键盘布局切换方法
本方法适用于所有 MX 系列键盘,非 MX 系列没有尝试,不保证可用。
罗技的 MX 系列键盘通常有两个布局模式,最主要的区别就在于底部的 start 按键和 alt 按键。
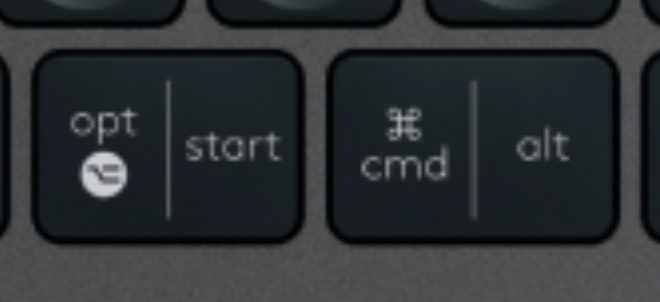
通过按键的标记可以看到,start 键(即 Windows 徽标键)在 mac 布局下是 opt 键,而 alt 键在 mac 布局下是 cmd 键。
但是这里的按键布局,翻遍了说明都没有找到如何切换。通过搜索发现,跟键盘第一次连接的设备有关。如果键盘第一次连接 mac,则使用左侧的 mac 布局。如果连接的是 Windows,则使用右侧的 Windows 布局。
这导致对双系统用户极度不友好。切换系统时,会出现按键标记与实际功能不符的情况。于是经过多方搜索,找到了手动切换布局的方法:
切换到 Windows 布局:按住 FN + P 键 3 秒(Hold FN+P for 3 seconds)
切换到 mac 布局:按住 FN + O 键 3 秒(Hold FN+O for 3 seconds)
GoLand 切换代码跳转时的默认系统
由于 go 原生支持了交叉编译,且允许自由的通过编译参数来做到多系统分别编译不同的代码,因此很多项目都实用这种方式来屏蔽跨系统的 API 差异。但是如果我们在非目标系统进行开发,如在 Windows 或 macOS 开发 Linux 程序,就会出现代码跳转的时候无法跳转到正确的文件。
这是因为 GoLand 默认使用我们开发环境的信息来搜索和跳转,因此如果在 Windows 开发,就会跳转到对应的 Windows 的实现。这时候,我们可以通过修改配置,来修改这一跳转行为。具体需要修改的配置为:
Preferences -> Go -> Build Tags & Vendoring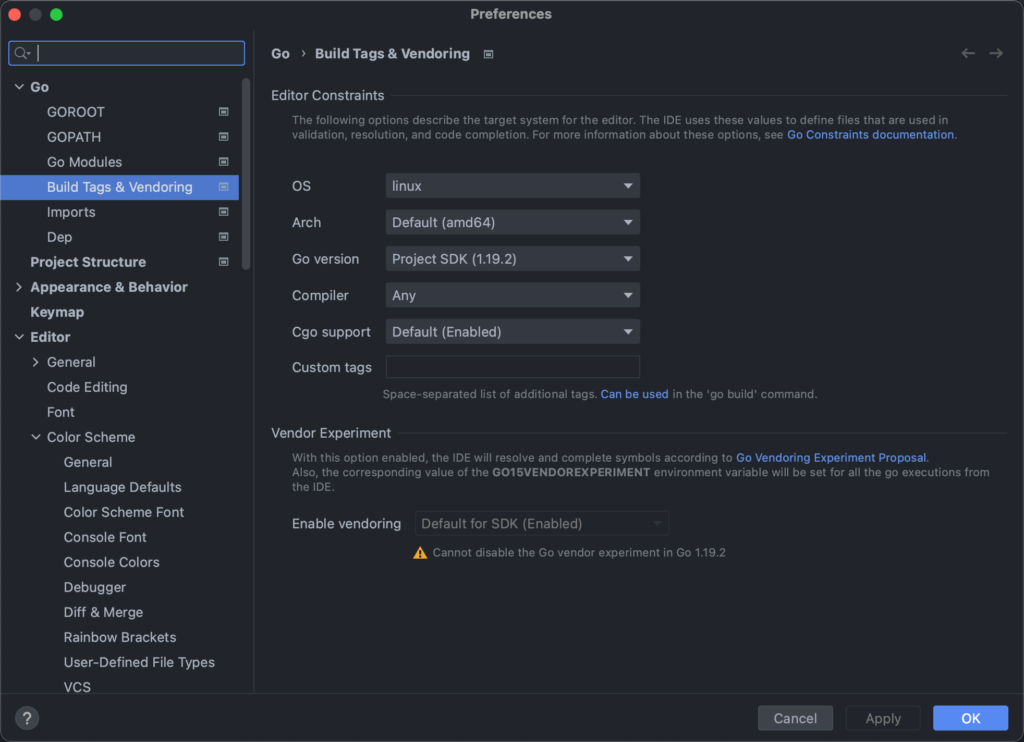
或者使用双击 Shift 输入 Build Tags 来快速定位到这个配置。
在这个配置里,将 OS 和 Arch 修改为目标系统即可。
设置完成后立刻生效,此时再跳转有多系统差异的函数,即可直接跳转到与设置对应的实现。
安全的调试容器内的进程
通常来说,使用 gdb 等工具调试测试或生产环境的进程,是非常好的查找 Bug 的方式。但是当我们步入容器时代后,使用 gdb 工具却会遇到一些麻烦。
当我们进入容器内,尝试使用 gdb attach 的方式开始调试已运行的进程时,会得到这样的报错:
Attaching to process 123
ptrace: Operation not permitted.
通过简单的搜索我们可以发现,这是因为容器内为了安全,默认没有给 SYS_PTRACE 权限的原因。于是,很多教程告诉我们,用这个命令启动容器解决这个问题:
docker run xxx --cap-add=SYS_PTRACE然而,在生产环境授予容器 SYS_PTRACE 权限是很危险的,有可能造成容器逃逸。因此,如果需要启用该权限,建议慎重考虑。
那么,有没有办法避开这个权限呢?由于容器本身其实就是主机上的一个进程,所以我们自然会想到,能否直接从主机找到对应的进程,然后在主机上执行 gdb attach 呢?
事实上我们可以这样操作,但是由于容器内的二进制文件在主机上并没有,所以 gdb attach 之后会报 No such file,并不能正常工作。就算我们把二进制拷贝出来,放在对应的位置上,gdb 还是会有 warning:
warning: Target and debugger are in different PID namespaces; thread lists and other data are likely unreliable. Connect to gdbserver inside the container.这个 warning 就是告诉我们,正在运行的 gdb 进程的 PID namespace 与想要调试的进程的不同,这会导致我们的线程列表等数据出现偏差,可能会影响调试。
考虑到容器的实现原理就是在不同的 namespace 中运行程序,因此如果我们能以容器进程的 namespace 启动一个调试器,那就能解决这个问题了。经过一番搜索,发现 Linux 提供了一个叫 nsenter 的工具来做这件事。我们只需要这样操作:
nsenter -m -u -i -n -p --target ${PID} bash
就可以启动一个跟容器内进程共用同一个 namespace 的 bash,并且该 bash 并没有 SYS_PTRACE 权限的限制,可以非常方便的使用 gdb 了。
深入理解 System.currentTimeMillis() 与时区
今天在解答同事对于 Unix Timestamp 的时区问题的疑问时,看到了这篇文章:
深入理解System.currentTimeMillis()
https://coderdeepwater.cn/2020/12/29/java_source_code/currentTimeMillis/
通过阅读发现,虽然该文章对于这个函数调用的原理解释的非常好,但是却在开头处犯了一个致命的错误,误导了我的同事。在这篇文章中,作者说:
深入理解System.currentTimeMillis()
System.currentTimeMills()的返回值取决于Java运行时系统的本地时区!千万不要忘记这一点!
同一时刻,在英国和中国的两个人同时用System.currentTimeMills()获取当前系统时间,其返回值不是一样的,除非手动将操作系统的时区设置成同一个时区(英国使用UTC+0,而中国使用UTC+8,中国比英国快8个小时).
这个观点是完全错误的,正因为这里的错误误导了我的同事,走入了错误的排查方向。
首先说结论:
System.currentTimeMillis()的返回值与系统时区无关。在一台时区和时间皆设置正确的机器上,这个函数的返回值总是当前时间与 UTC 0 时的 1970年1月1日 0时0分0秒即1970-01-01 00:00:00 UTC的差值- 同一时刻,在地球上任意地点的两个人在时区和时间皆设置正确的机器上同时用
System.currentTimeMills()获取当前系统时间,其返回值一定一样,与时区无关
首先明确几个概念:
- 时间:是一个客观存在的物理量,是物质运动变化的表现
- 时间单位:人为了方便对时间进行计量,人为定义了年、月、日、时、分、秒、毫秒等一系列时间单位
- 公历日期:人为规定的纪年体系,用来记录准确的时间
- 时区:由于地球自转的存在,地球上各个地区的日升日落时间并不一致。因此为了使用方便,人为将地球划分成了 24 个时区,每两个相邻时区间的时间表示相差 1 小时
- Unix 时间戳:人为规定的用来描述一个确切时间点的系统。以
1970-01-01 00:00:00 UTC为基点,计算当前时间与基点的秒数差,不考虑闰秒
从这几个概念中,我们可以知道,Unix 时间戳是用于精确描述一个确定的时间点,具体的方式是计算两个时间点之间的秒数差。由于我们的宇宙只有单时间线,所以计算两个确定的时间点之间的秒数差,在地球上任何地方的时间都是一致的。因此我们可以知道,在一个确定的时间点上,地球上所有人计算得到的当前的 Unix 时间戳,都应当是一致的。
那么,为什么还有人遇到不同时区获取到的时间戳不一致的问题呢?这就要说到实际使用中对时间的展示方式了。
一个简单的例子,如果我说现在是北京时间 2020年01月01日 08时00分00秒,那么这可以表示一个准确的时刻。对于同一个时刻,我还可以说,现在是格林威治时间 2020年01月01日 00时00分00秒。这两个句子实际上表达的是同一个时刻。
但是,如果我只说现在是 2020年01月01日 00时00分00秒,那么不能表示一个准确的时刻。因为在句话里,我没有说明时区信息,导致缺失了定位到准确时刻的必要条件。
因此我们可以发现,我们日常说话时的表述,其实都是不精确的。那么在程序员的世界里,我们最容易犯的错误,也跟这个类似。
当我们查看一个服务器的时间信息的时候,大多数人不会关心时区信息。假设现在有一台 UTC 0 时区的服务器,很多人拿到后,在检查服务器时间时,第一反应是这个服务器的时间不对,因为桌面上的时钟是 2020年01月01日 08时00分00秒,而机器告诉我的是 2020年1月1日 00时00分00秒,晚了 8 小时。于是,使用 date -s "2020/01/01 08:00:00" 一把梭,再看机器的时间,完美!
那么这时候,如果我用 System.currentTimeMills()来获取时间戳,得到的是什么呢?得到的当然是 1577865600000,代表北京时间 2020年01月01日 16时00分00秒。因为机器本身运行在 0 时区,对于机器来说,现在是 0 时区的 8 点,那换算到 +8 的北京时区,自然是 16 点。
这也就是前面为何一直强调时区和时间皆设置正确的原因。刚说的案例就是典型的时间与时区设置不匹配。机器的时区是 0 时区的,但是用户设置进去的时间却是 +8 时区的。在这种情况下,System.currentTimeMills()自然获取不到正确的值。
因此,我们在修改机器的系统时间时,一定要带上时区信息。如:date -s "2020/01/01 08:00:00 +8" 。这样就可以准确的告诉系统我们想要设置的时刻,避免因为自动的时区转换导致调错机器的时间。